


現在關鍵是算力提供者NVDA的moat還會有多久
快速總結 -
目前要time-to-market nvda就是唯一首選
(
datapoint 1: 雖DS 證明有能力玩GPU底層 但還是選經過驗證過的NVDA玩 不玩AMD的GPU避免浪費投入
datapoint 2: TLSA玩過自己的Dojo後 還是對老黃說 你有多少 我就買多少
datapoint 3: 還沒看到nvlink的競爭者產品
)
(
nvlink的競爭者 -
UAlink 是雜牌軍 目標容易相互衝突 我不看好:
AMD/Intc/MSFT/META/Goog 要"big pipe" 大又便宜的管子
CSCO/HPE 要smart pipe 所以可以賣 switching features
)
=======
SW
OpenAI / Mag7 - 1 都在攻CUDA的moat
真要知道 CUDA 的software stack moat 看這個:
CUDA moat 不是純然是技術面 更多的是因為法律面
在HW
AI 競爭的底層邏輯 要從 Data傳輸想
- memory wall
- network for scaling up
https://www.mobile01.com/topicdetail.php?f=291&t=6512441&p=134#87756537 一連好幾樓
(另詳情請google: AI Memory Wall)
目前沒有一家有像NVDA是單機+網絡 全系統整合的解
這還是從一個門外漢的角度
其中一定還有其他不為人知的眉角
例如 AMD各個零件規格都比NVDA強
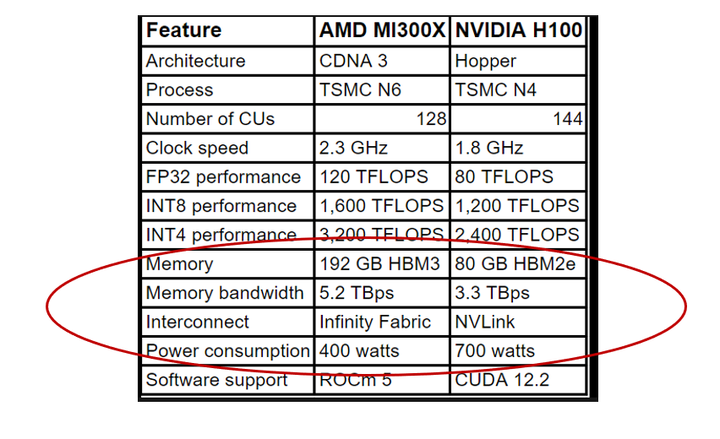
但整體性能就是沒有NVDA好
https://semianalysis.com/2024/12/22/mi300x-vs-h100-vs-h200-benchmark-part-1-training/#detailed-recommendations-to-amd-on-how-to-fix-their-software
所以 SW + HW
目前 你要time-to-market nvda就是唯一首選
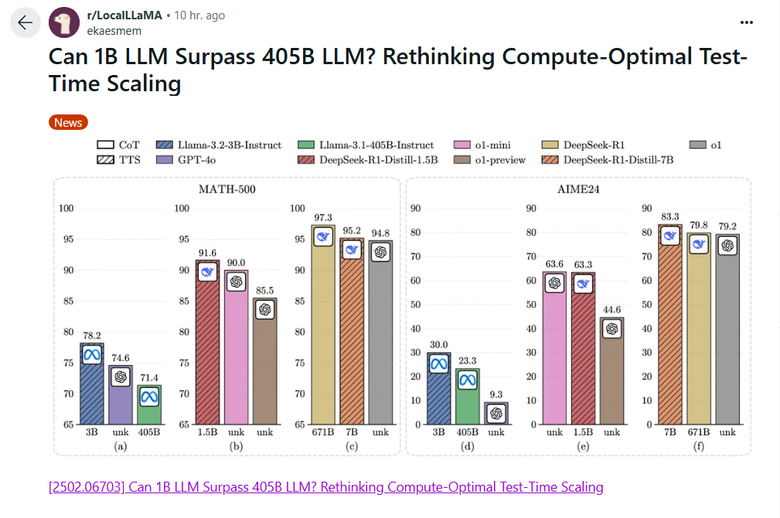
https://www.reddit.com/r/LocalLLaMA/comments/1inieoe/can_1b_llm_surpass_405b_llm_rethinking/
不知為什麼這GPU killer paper過兩天才在傳
這種發展會把巨型data center需求大幅降低
這一波AI-HW near over, if not over
AI 發展太快了

Mavs41Forever wrote:
AI 發展太快了
OMG 又一個mega-data-center killer project
1.5B Model > OpenAI
https://github.com/agentica-project/deepscaler
We introduce DeepScaleR-1.5B-Preview, trained on 40K high-quality math problems with 3,800 A100 hours ($4500), outperforming OpenAI’s o1-preview on multiple competition-level math benchmarks.
DeepScaleR-1.5B-Preview,它經過 3,800 個 A100 小時的 40K 高品質數學問題訓練(4500 美元),在多個競賽級別的數學基準上優於 OpenAI 的 o1-preview。

普羅米修斯已經把Mag7獨享的火種傳給一般的普羅大眾了




























































































內文搜尋