
不太理解,但感覺有點厲害
====================================================
小米聲音理解大模型MiDashengLM-7B 全面開源
2025-08-04 12:57 聯合報/ 記者
賴錦宏
《IT之家》4日消息,小米自研聲音理解大模型「MiDashengLM-7B」今天正式發布,並全量開源。小米表示,,MiDashengLM-7B速度精度上實現雙突破:單樣本首Token延遲僅為同類模型1/4、同顯存下並發超20倍,在22個公開評測集上刷新多模態大模型最佳成績(SOTA)。
報導稱,MiDashengLM-7B基於Xiaomi Dasheng作為音訊編碼器和Qwen2.5-Omni-7B Thinker作為自回歸解碼器,透過創新的通用音訊描述訓練策略,實現對語音、環境聲音和音樂的統一理解。
2024年,小米發布的Xiaomi Dasheng聲音基座模型,據稱是國際上首次突破AudioSet 50+ mAP,在HEAR Benchmark環境聲、語音、音樂三大領域建立領先優勢並保持至今。
Xiaomi Dasheng在小米的智慧家庭和汽車座艙等場景有超過30個落地應用。業界首發的車外喚醒防禦、手機音箱全天候監控異常聲音、「打個響指」環境音關聯IoT控制能力,以及小米YU7上搭載的增強哨兵模式劃車檢測等,背後都有Xiaomi Dasheng作為核心演算法的賦能。
MiDashengLM的訓練資料由100%的公開資料構成,模型以寬鬆的Apache License 2.0發布,同時支援學術和商業應用。
小米表示,不同於Qwen2.5-Omni等未公開訓練資料細節的模型,MiDashengLM完整公開了77個資料來源的詳細配比,技術報告中詳細介紹了從音訊編碼器預訓練到指令微調的全流程。
作為小米「人車家全生態」策略的關鍵技術,MiDashengLM透過統一理解語音、環境聲與音樂的跨領域能力,不僅能聽懂用戶周圍發生了什麼事情,還能分析發現這些事情的隱藏含義,提高用戶場景理解的泛化性。
基於MiDashengLM的模型透過自然語言和用戶交互,為用戶提更人性化的溝通和反饋,例如在用戶練習唱歌或練習外語時提供發音回饋並制定針對性提升方案,又例如在用戶駕駛車輛時實時對用戶關於環境聲音的提問做出解答。
MiDashengLM以Xiaomi Dasheng音訊編碼器為核心元件,是Xiaomi Dasheng系列模型的重要升級。在目前版本的基礎上,小米已著手對該模型做運算效率的進一步升級,尋求終端設備上可離線部署,並完善基於使用者自然語言提示的聲音編輯等更全面的功能。
在過去12個月裡,中國模型已經超越並擴大了對美國開放式模型的領先優勢。

中國的領先地位也影響研發部門以及那些使用開放模型的開發者。過去,美國和歐盟曾共同領先,但現在,在 huggingface 上上傳的新微調中,中國佔據了絕對多數(僅 Qwen 模型就佔了約 40%,Qwen 模型目前是領先的系列)。

ATOM:真正開放的美國模型
ATOM 計畫
邁向為美國科研與產業打造的完全開放模型
重新振興美國的人工智慧研究,從國內打造領先的開放式模型開始
美國在人工智慧領域的領先地位,是建立在其作為全球開放AI研究樞紐與領先生產者的基礎上。正是這些研究催生了如 Transformer 架構、ChatGPT,以及近來的推理模型與智慧代理系統等創新。然而在當前地緣政治不確定性與中美緊張關係升溫的背景下,美國正處於失去這一領導地位的邊緣。
美國最優秀的AI模型正趨於封閉與限制,而中國的模型卻日益開放,迅速搶佔美國與全球研究機構與企業的市場份額。
開放語言模型:AI領導地位的根基
開放語言模型正成為AI研究的基石與競爭力的關鍵工具。然而美國在這一領域的表現與採用率雙雙落後,未來更有可能進一步落後。
美國必須重新掌握全球AI研究主導權,並投資於開發研究人員所需的工具:一套領先的、開放的基礎模型,重建強健的研究生態系統。
全球模型動能轉移
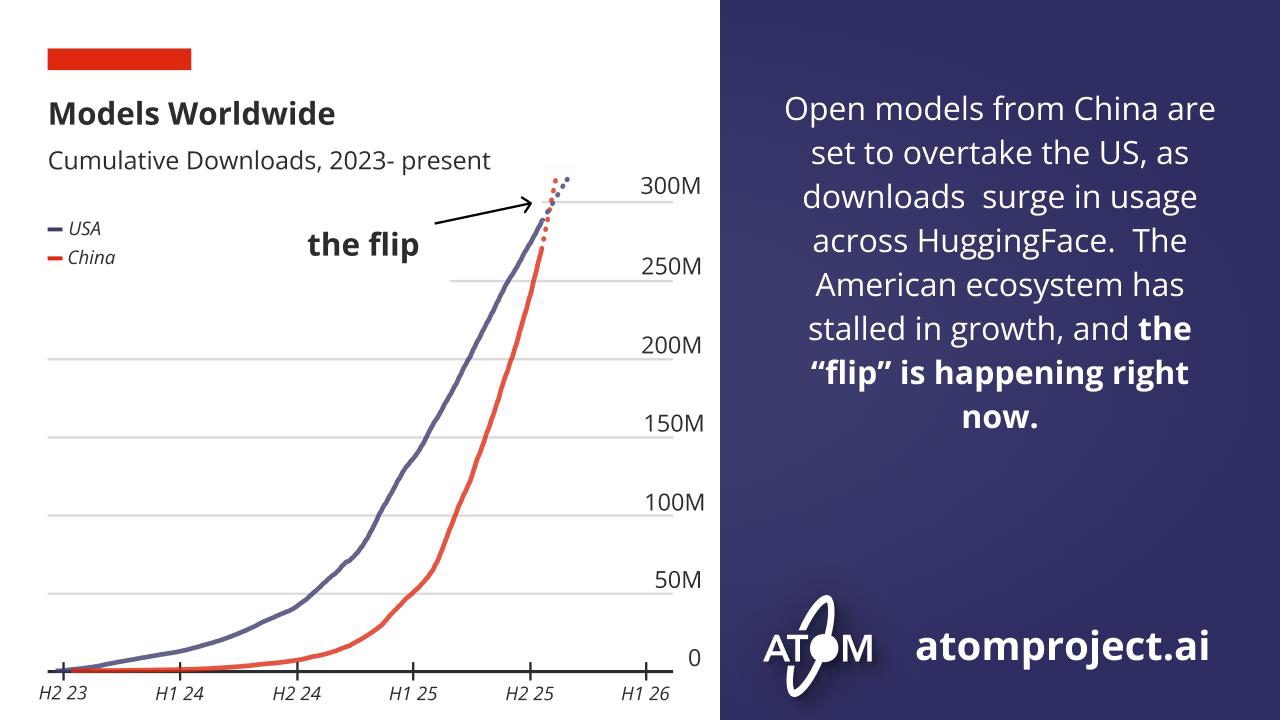
來自中國的開放模型即將超越美國,HuggingFace平台上的下載量激增,美國生態系統則停滯不前。這場「翻轉」正在發生。
模型全球下載總量(2023年至今)
累計下載量(單位:百萬)
美國、中國、歐盟呈現交叉變化趨勢,中國正急起直追。
ATOM 計畫建議
若美國希望重新取得開源AI的全球主導權,需維持多個研究實驗室,配置超過10,000張先進GPU,用於訓練開放模型。
中國目前至少有五個實驗室生產並發布性能與美國最佳開源模型相當或更強的開放模型。重新取得開源主導地位,是推動基礎AI研究、提升美國AI市佔率,並確保AI技術堆疊安全的必要條件。
概覽
開放語言模型的權重與訓練數據是當代 AI 研究的核心資產。這些公開資源促使新模型架構、訓練方法與工具的誕生,可能催生出下一個足以顛覆「Transformer」或「推理時可擴展性(Inference-time Scaling)」等現有典範的創新技術。
這些研究進展不僅推動現有產品的持續優化,也為新創科技企業奠定基礎。同時,開放語言模型讓任何人都能依照自身需求開發與修改AI,無需將數據傳送至封閉供應商的雲端,拓展了AI應用的多樣性與可能性。
開放語言模型:維繫美國產業競爭力的關鍵
當今相當多創新仍集中於大型封閉AI實驗室,但這些組織的資源多用於訓練下一個模型,涵蓋範圍有限。相較之下,開放研究社群則聚焦於未來2年、5年、甚至10年後具有顛覆性的創新。
要建立真正有用與智慧的AI系統,需讓更多人能夠參與,而不僅是少數特定企業的工程師。
美國曾是開放AI生態系的核心
這個生態系的特點,是多方參與與協作。美國能在深度學習革命中扮演關鍵角色,正是因為科技企業與學術機構緊密合作。然而,自 ChatGPT 問世後,全球的研究重心已逐漸偏向中國,原因在於中國對「開放創新」的堅持,而美國許多頂尖科學家則轉入封閉研究組織。
美國創建 Transformer 架構的成功經驗,如今正被中國企業採用
Transformer 架構的誕生是由 Google 開創並分享的,它是現今所有主流大型語言模型(如 ChatGPT、Gemini、Claude)的技術基礎。然而這樣的「開放分享」模式,如今卻逐漸被美國企業忽略,反倒被中國企業奉為準則。
中國的進展,源於開放模型研究的制度與資源
中國開放模型的成長,離不開兩項關鍵資源:
1. 大量計算資源(與AI實驗室與高校的合作)
2. 國家支持的研發與釋出計畫
除非美國及其盟國直接投資於高效能的開放模型訓練與流程分享,否則AI研究的進展速度將持續落後。
建立世界領先的開放模型需要高資本密度與人才集中
目前要訓練性能最強的開放模型,開發者需要巨額資本與世界級人才。我們估計,美國若想重新領先,需投資多個由超過10,000顆 H100 GPU組成的叢集,以打造完整的開放模型生態,並促進西方AI研究的復興。
若將這類大型投資分散於過多小型專案,將因計算資源不足而無法培養出領先模型。
同時,我們也需要開發各種規模的開放模型,以支援從本地設備到雲端高效能計算的各類AI應用。
開放模型是AI研發的引擎
美國的AI領導地位,是由數以萬計的學生、學者與研究人員歷經數十年辛勤建立而成。但在邁向語言模型主導的新時代之際,這個體系正面臨斷裂危機。
自 ChatGPT 問世後,開放語言模型與計算資源已成為能否進行重要研究的「入場券」。高品質的開放模型與其技術報告迅速獲得數千次引用、榮獲最佳論文獎,並吸引大量學生投入研究。
不只是學術界,企業也將受益於開放模型
開放模型的低成本、高靈活性與可定製性,使其非常適合多數商業用途。無論是大型企業或初創公司,都能從美國新一波開放模型中受益。
如果美國不再持續打造領先的開放模型,那麼本國研究人員與企業的注意力將繼續流向海外。歷史上,技術開放分享的好處,總是回饋給分享者本身,包含聲望、話語權與生態系主導權。如今這些好處正在流向中國,因為他們積極支持開放模型。
中國正在使用美國當年奠定AI領導地位的開放創新策略
這帶來了快速創新、國際採用率提升與研究吸引力上升。美國的AI研究優勢瓦解,不只是因為中國模型品質卓越,也因為中國堅守「開放模型原則」——這正是美國科學家當初開創AI革命的基礎。
值得注意的是,中國釋出的開放模型,其使用授權往往比美國模型更加寬鬆。
封閉實驗室與美國研究生態的失衡
美國眾多領先的封閉研究機構仍在持續打造世界級模型,這些成果確實非常傑出。然而,封閉實驗室產出的研究也往往是封閉的,而過去AI的快速進展,是建立在開放協作與世界級美國模型的基礎之上。
作為研究人員,我們專注於未來核心技術的研發,但我們也愈來愈關注缺乏強大開放模型所帶來的國安與政策風險:
美國與其盟友在某些領域對中國開放模型的採用速度緩慢,主因是擔心模型暗藏後門或生成程式碼的安全性不足。
同樣,也有擔憂中國模型輸出的內容經過審查,或不符合美國對自由、平等與獨立的價值觀。
中國開放模型的快速擴張,甚至被認為與中國過去的策略類似——透過國家補貼的低價出口,削弱美國競爭對手。
這項技術正在迅速發展,我們必須先發制人,否則使用習慣、成本劣勢與其他誘因將使得美國開放模型的實際採用變得越來越困難。
中國模型動能正全面超越美國
中國開放模型即將在不久的未來全面超越美國,Qwen 模型在 HuggingFace 平台上的下載量激增就是明證。
趕上 LLaMA 的步伐
累積下載量(2023年至今)
2023年12月 – 2025年7月
Llama
Qwen
Mistral
DeepSeek
📊 來源:HuggingFace – ATOM 計畫整理
各地區模型採用趨勢
每月新開源微調模型占比(依模型原創者地區)
2023年11月 – 2025年7月
中國從原本的次要角色,已在2025年全面領先
美國與歐盟則逐月下滑
📊 來源:HuggingFace – ATOM 計畫整理
美國在開放模型性能上已失去領先地位
在無數基準測試中,美國主導的開放模型已被中國模型超越:
2024年7月,美國的 Llama 3 模型曾短暫領先中國的開源模型
但隨後中國的開放模型供應商數量快速增加,並進一步拉開差距
美國主要的開放模型來自 Meta(Llama)與 Google(Gemma),中國則以 DeepSeek 與阿里巴巴的 Qwen 為代表。不過,如今還有更多新創如 Moonshot AI(Kimi)、智譜 AI、騰訊等也迅速逼近。
中國模型稱霸全球排行榜
我們引用兩個代表性的公開綜合排行榜:
1. LMArena: 群眾評比排行
2. ArtificialAnalysis: 綜合多項能力測試的智慧表現總排名
目前在 LMArena 排行榜上,前十名開放模型皆來自中國。
在 ArtificialAnalysis 的排名中,截至 2025年8月4日,前3名開放模型全為中國出品。
Llama 的孤軍奮戰與限制
Meta執行長馬克·祖克柏是少數明確主張美國應長期投入開放模型的企業領袖之一。Llama 系列模型自 ChatGPT 發布以來,成為學界與產品開發的重要基礎:
第一代 LLaMA 系列包括 7B、13B、32B、65B 參數模型,因便於微調與推論,成為研究預設模型
Qwen 1.5 系列於 Llama 2 發布後不久推出,起初 Llama 2 的總下載量為 Qwen 的 5 倍(Llama 2 的 4 款模型約 6000 萬下載次,Qwen 初代 8 款模型共 1000 萬)
Llama 3 系列在 2024 年持續推出,其部分子版本(如 Llama 3.1、3.2)曾創下 HuggingFace 平台歷史最高人氣。然而到了 Qwen 2.5 系列問世時,雙方總下載量差距已縮小至約 2000 萬(Llama 3 約 1.4 億,Qwen 2.5 約 1.2 億)。
授權限制與生態系挑戰
Llama 的成功雖基於強大性能與既有分發網路,但其授權條款偏嚴格,用戶須細讀條文以確保合法使用。
反觀 Qwen 與其他中國模型多採取開源軟體慣例的簡化授權,降低用戶採用門檻。
Meta 幾乎是美國唯一持續定期發布開放模型的企業;而中國則擁有如 DeepSeek 與 Qwen 這樣可媲美 Meta 的開源模型家族,涵蓋不同規模,支援各種應用。
美國 vs. 中國:一人對五人的賽跑
中國目前已有五家世界級開放模型實驗室,數量還在成長;而美國僅有 Meta 這位「獨行者」代表美國參賽。
我們讓 Meta 一人與中國五隊競爭,卻在其無法次次奪冠時指責其落後。問題不在於「Llama 4 不夠先進」,而在於美國生態系根本沒有形成完整團隊。
中國開放模型即將成為歷史上採用率最高者
根據我們從全球六大開放模型供應商收集的歷史下載數據(Meta、Google、Mistral、微軟、Qwen、DeepSeek),可以看到以下趨勢:
美國初期依靠 Llama 保有領先地位
歐洲因 Mistral 的爆紅一度逼近
中國則持續加速,如今已在 2025 年夏季全面超越美國
截至 2025 年 8 月,中美雙方最熱門模型均達 約 3 億次總下載量,但中國的成長速度明顯更快。
微調模型與社群使用趨勢
微調(finetune)是讓模型針對特定任務更有效的核心流程,對學術研究與商業應用皆至關重要。
2024 年初,中國模型佔 HuggingFace 新微調模型的 10–30%
如今僅阿里巴巴 Qwen 系列就佔 HuggingFace 每月新語言模型衍生品的 超過 40%
反觀 Llama 的衍生模型市佔率,從 2024 年秋季的接近 50% 峰值,已下滑至僅 15%
美國與歐洲新推出的開放模型選擇明顯減少,中國模型的生態佔比預期將持續上升。
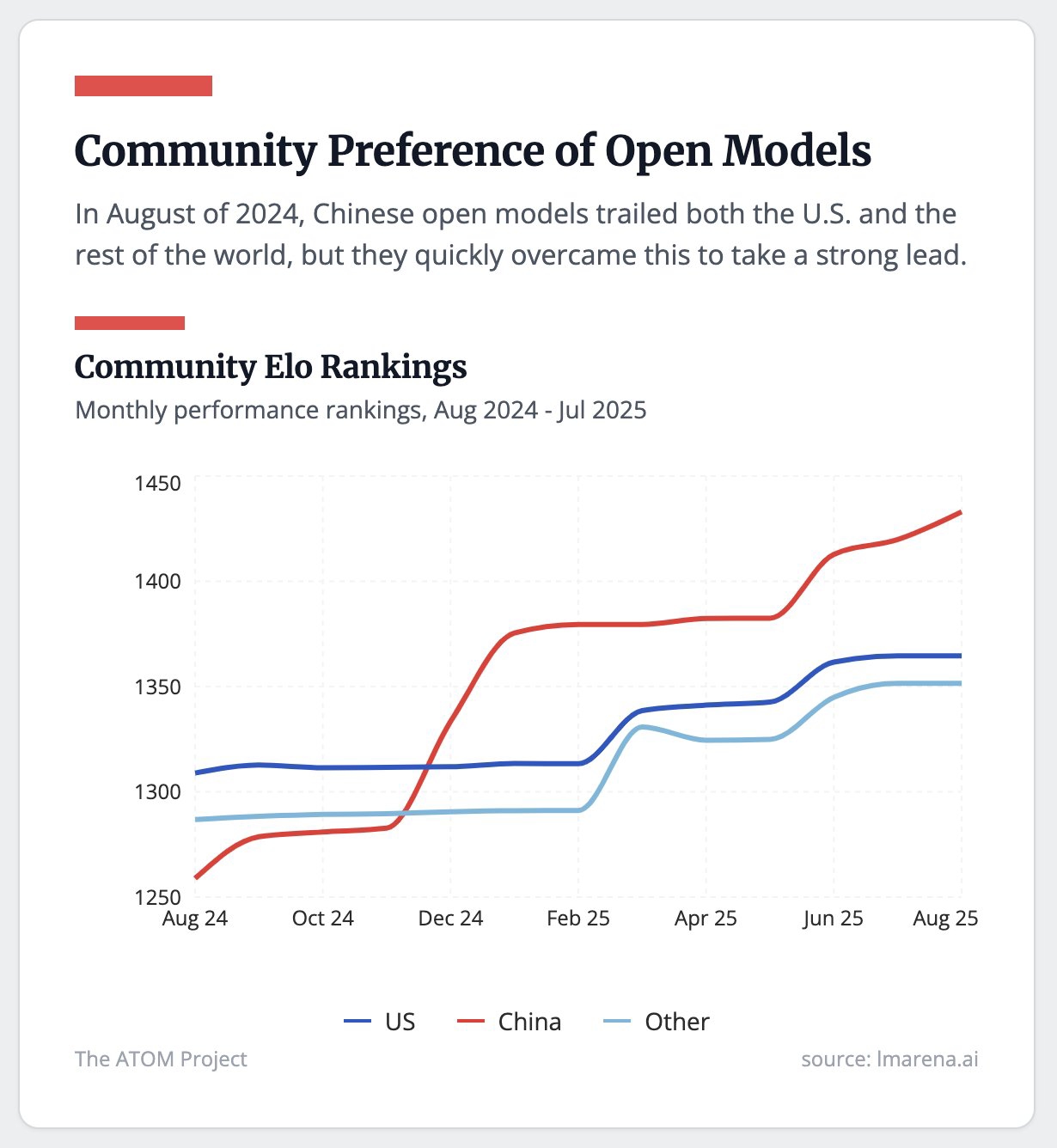
社群對開放模型的偏好正在改變
2024 年 8 月,中國開放模型在社群評價中仍落後於美國與其他地區模型;但不到一年,它們迅速反超,並奠定領先地位。
社群 Elo 排名趨勢
> 每月表現排名(2024 年 8 月至 2025 年 7 月)
Elo 評分範圍約為 1250–1450
📈 排名變化如下:
美國:從高點一路下滑
中國:穩步上升,至今領先
其他地區:變化有限,略微下滑
📊 資料來源:lmarena.ai – ATOM 計畫
歐亞美開放模型性能長期走勢分析
人工智慧表現排名趨勢(ArtificialAnalysis 評分)
> 各地區整體智慧表現:2024 年 4 月 – 2025 年 8 月
分數範圍:從 15 到 75(越高代表綜合能力越強)
📈 結果趨勢:
美國:起伏不定,2025年以來未見成長
歐洲:穩定但偏低
中國:持續增長,至 2025 年中全面領先
📊 資料來源:artificialanalysis – ATOM 計畫
衍生模型的釋出趨勢(依模型原創者)
此圖顯示每月釋出之微調/衍生模型,以底層原始模型所屬的公司或組織為分類依據。
衍生模型佔比走勢(2023 年 11 月 – 2025 年 7 月)
📈 數據觀察:
Qwen(中國):已成為全球最大衍生模型來源
Meta(美國):市佔持續下滑
Mistral(歐洲):曾短期領先,但後繼乏力
📊 來源:HuggingFace – ATOM 計畫
結語:美國需要的不只是模型,而是生態系
目前的現實是——中國模型正在全球擴張,美國則靠著 Meta 一家公司獨撐局面。這不是技術實力的問題,而是生態建設失衡的體現。
想要在AI這場未來決勝的技術競賽中重拾領先地位,美國不僅需要一個 Llama,而是需要十個、二十個類似 Llama 的模型與背後的團隊,建立一個真正開放、協作、共享的研究與開發體系。
開放模型不只是科研利器,更是美國產業創新的基石、AI主權的保障、全球價值觀的延伸工具。
我們不能再等。
✅ 支持 ATOM 計畫:重建真正屬於美國的開放式 AI 模型。
📩 [簽署連結與聯絡方式(略)]





























































































內文搜尋
X