
由Google旗下人工智慧部門DeepMind所開發的人工智慧軟體「AlphaGo」推出後,在圍棋世界掀起一滔天巨浪,透過智慧演算先是擊潰南韓棋手李世乭,接著打敗世界第一棋手柯潔。如今,DeepMind又開發出一款「AlphaStar」,主要挑戰即時戰略遊戲《星海爭霸2》,而AlphaStar於今(25)日正式登場,輕鬆以2個5:0,擊敗世界排名第13、44的職業選手。
▲Google推出人工智慧「AlphaStar」,擊敗職業選手。(圖/翻攝自星海爭霸臉書)
綜合外媒報導,於台灣時間25日凌晨2時,DeepMind與知名遊戲商暴雪娛樂(Blizzard Entertainment)合作,同時正式亮相最新人工智慧AlphaStar,在與職業選手對戰前,DeepMind執行長哈撒比斯(Demis Hassabis)表示,《星海爭霸2》是一款相當複雜的即時戰略遊戲,對人工智慧是一大考驗。
然而這次的比賽,是透過直播回放畫面,與實際的「人機大戰」相隔2周時間,但AlphaStar的能力卻讓大家相當震驚。AlphaStar分別以2個5:0,擊敗界排名第44位的職業選手TLO和世界排名第13位的MaNa,這也讓外界再次對人工智慧的能力感到震驚。
更專業的分析在這裡
多圖詳解 DeepMind 的超人類水準《星海爭霸》AI「AlphaStar」
原來阿爾法狗可以開始打星海了喔?
還贏了職業選手,即時戰略遊戲這麼複雜深度學習能贏玩家嗎?
哪時候阿爾法狗可以讓LEVEL 5級 自動駕駛汽車上路?
可以解放駕駛員
文章第二個連結分析 3個重點
1.說阿爾法SATR的14天訓練程度相當於人類玩200年場次的星海
(儘管每1場阿爾法星的學習效率低於人類 因為人類和電腦用不同的方式學習)
2.以及限制微操作次數到比人類還低的APM
3.就算限制阿爾法STAR的視窗框移動
最後還是超過了人類.........
由於 AlphaStar 首先從人類玩家資料模仿學習,以及神經網路有一定的計算延遲,操作頻率其實比人類選手還低一些。MaNa 的 APM 達平均 390,AlphaStar 平均只有 280 左右。AlphaStar 的計算延遲平均為 350 毫秒(從觀察到行動)。相比之下,以往基於固定策略和手工規則的星海 AI 會保持上千 APM。
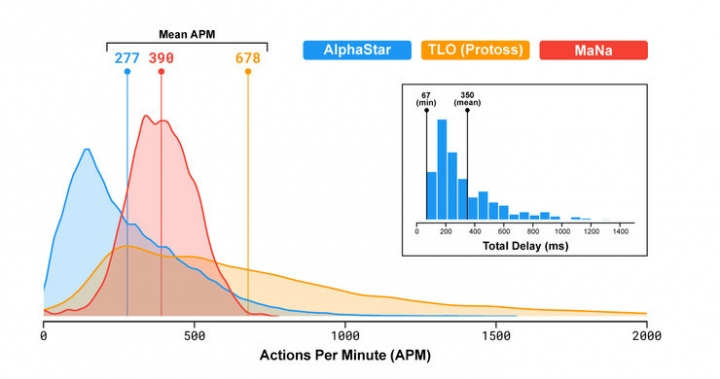
所以說阿爾法星海APM微操作次數並沒有比人類還高

限制視窗移動效果還是一樣 只是成長慢一點而已最終還是超過人類






























































































