為什麼中學生要學AI程式?
科技已成為當代人類社會最強生產力,尤其過去50年以指數成長的半導體與數位科技,帶動其他科學與經濟發展,如今數位科技以 AI 最令人矚目,影響力將超過網際網路與智慧型手機,是帶動未來30年全球發展的火車頭。
網際網路與智慧型手機在過去20年已改變全世界所有人的生活習慣,也顛覆各行各業的規則,影響力不可謂不大,人工智慧有可能超越他們嗎?人工智慧對人類的影響能有多大?著名作家哈拉瑞的答案相當令人吃驚,在《21世紀的21堂課》書中指出,未來威脅人類生存的三大危機,包括核戰、氣候變遷以及科技顛覆,其中顛覆性科技主要指人工智慧(AI)與生物科技(Biotech)。
也就是說,人工智慧的潛力完全能夠與核能相提並論,用得好,能改變世界、創造幸福;用不好,極可能毀滅人類文明。人工智慧與核能、氣候變遷將是未來30年最重要的議題,受影響最大的,莫過於現在的中學生,他們未來的命運應該掌握在自己手裡。
簡單地說,人工智慧的力量非常巨大,不論對個人或國家,能否善用這股力量,將決定未來的命運,越早開始學習越好,中學生已具備學習人工智慧的部分基礎知識,應儘快有系統的學習。
當然,現有人工智慧(機器學習)背後的原理,牽涉到高等數學,包括線性代數、微分方程、機率統計等,必須等到大學或研究所再修。對高中程度而言,可以先學習基礎的AI程式設計,也就是利用Apple原廠框架裡面的物件,寫出基本的人工智慧應用程式。
人工智慧是如何變厲害的?
人工智慧(Artificial Intelligence, AI)最近的進展,可說風起雲湧,稱得上是當今數位科技最大的突破與成就之一,現在的AI不但各國語言聽說讀寫翻譯樣樣通,就連下棋、作曲、寫詩、繪畫、開車、送貨…也都不在話下。生活中已可看到各類AI產品,包括:
- 語音助手及智慧喇叭:如 Apple Siri, Google Assistant, Amazon Alexa, …
- 自動駕駛汽車:如特斯拉(Tesla)、Google Waymo…
- AI機器人:如第一位獲得中東國家公民權的AI索菲亞(Sophia)、日本軟體銀行的Pepper…
- 聊天機器人:ChatGPT 號稱是目前最強聊天機器人
- AI換臉/修臉:DeepFake, Toonify, 美顏相機…
- AI繪圖:Midjourney, Stable Diffusion, DALL-E, …
- 無人商店/自動化餐廳/無人機送貨/停車場車牌辨識…
AI不但藏身於每個人的手機,也出現在各式各樣的智能機器中,雖然尚未有單一AI融合所有技能,大多只擅長其中一項,且精確度未必都令人滿意,但已顛覆大家對機器的認知,令人不禁要問:機器真能具備人類智慧嗎?
要回答這個問題,就不得不提到兩位被尊稱為「人工智慧之父」的先驅人物。第一位是有現代電腦之父與人工智慧之父雙重頭銜的英國人艾倫.圖靈(Alan Turning),在1950年代研究「計算機器」能否具備人類思考與推理的能力,並且制定一個判斷機器能否模擬人類智慧的測試,稱為「圖靈測試」,如今若有機器或電腦程式能通過圖靈測試,基本上就認定能模擬人類的推理能力或智慧。
圖靈也是最早的程式設計師之一,在1948年設計過一個西洋棋遊戲(的演算法),但當時電子計算機剛發明,沒有任何程式語言,實際上並沒有任何機器可以執行這個遊戲。類似於此,1950年圖靈純粹從理論設想了一個「模仿遊戲」:如果有機器與真人對談一段時間而不被發現,就算模仿成功,通過測試。
“Artificial Intelligence” 一詞的創造與相關研究,則由另一位人工智慧之父 — 美國人約翰.麥卡錫(John McCarthy)1955年左右開始推動,他從人類如何推理、理解語意開始,設法將推理邏輯與語意規則寫成程式,這是一個非常困難且無比複雜的挑戰,他甚至創出一個程式語言 LISP 來開發人工智慧程式。
很可惜,麥卡錫花了40年都無法通過圖靈測試,不過卻在人工智慧領域開拓出廣大空間。1980年之後,其他科學家改用其他不同方法模擬人類智慧,其中包括「神經網路」、「機器學習」等,以數學統計為基礎的方法,並不直接找出準確的答案,而是從大量數據學習中,趨近可接受的答案。
神經網路與機器學習的方法,初期還是遭遇許多困難,經過30年的發展,在網際網路普及之後,有了網路上大量數據為基礎,終於在2010年左右開始有程式通過圖靈測試。如今若與 ChatGPT 對談,不但會以為跟真人無異,還會覺得比人更聰明,已然超越圖靈測試。
人工智慧與一般程式有何不同?
隨著人工智慧的新聞熱度越來越高,人工智慧似乎無所不在、無所不能,好像很厲害的樣子,有什麼是人工智慧做不到的嗎?
其實,人工智慧只是電腦軟體的一種,所能做的事情並不會超出軟體的範圍,只不過隨著軟體應用越來越廣,生活中能承載軟體的數位設備越來越多,讓人工智慧影響力也逐漸擴大。
那麼,同樣都是軟體,人工智慧程式與一般程式又有何不同呢?如果真要比較的話,兩者倒有個非常明顯的區別,就是「因果關係」。
在我們前面課程中,所有範例程式都有一個特點,就是不管在誰的設備上執行,都會得到相同結果,也就是結果並不隨著時間、地點、環境而變化,只要程式與輸入條件沒變,輸出就會相同。種什麼因,得什麼果,因果關係非常明確,寫程式的人完全可以預期程式執行的結果。所有程式不應該就是這樣嗎?
人工智慧程式並非如此,同樣的程式與輸入條件,在不同時間可能產生不同的結果,而且連寫程式的作者,也無法預期執行的準確結果。為什麼會這樣?下一節我們會以最近非常熱門的 ChatGPT 人工智慧程式來當例子,實際觀察一下這個現象。
但為什麼人工智慧程式不像一般程式那樣,完全根據輸入產生唯一的結果,這樣既容易預期,也好判斷對錯呢?簡單的說,因為人工智慧程式所針對的問題,大多沒有明確答案,就像下棋,在任一時間,問下一步下在哪個位置贏面最大?這就產生很多選擇,甚至可能沒有一個正確答案。
為了達到圖靈與麥卡錫所期望,讓電腦也能夠理解人類的智慧,目前人工智慧程式大多採用數學上的統計模型來「趨近」答案,也就是說,AI 每一次回答,其實都帶有隨機性,即使相對較明確的答案可能是代表99.9%機率(有0.1%機率會出現其他結果),不像一般程式那樣,100%一定都是同樣結果。
人工智慧包含哪些領域?
想想看人類的智慧從何而來。當過父母的都知道,嬰兒一歲之前就能透過「聽覺」學習詞彙,兩歲前已會用「視覺」協調肢體動作,三歲就開始有自我意識,能分辨你我他,並用「語言」與人交流。接下來開啟後天學習,透過書本、影片或實物學會辨識各種物體與知識:這是大象走很慢、這是牛奶可以喝、大海裡面有很多魚會游泳…,人類智慧就像這樣,一點一滴累積而來。
由此可知,人類的智慧大都透過視覺與聽覺所獲得,再加上以文字紀錄、用語言交流。因此,人工智慧程式基本上有個目標範圍,就是針對「視覺、聽覺、語言」等三方面的應用。所以,若程式能夠分辨各種物品,聽懂日常對話,或能運用語言與人類雙向交流,我們就認為是合格的人工智慧。
本單元內容大綱
不可諱言,目前人工智慧程式的電腦語言,使用最多的是 Python,不過,從語言特性與應用層面來看,Python 有許多地方比不上 Swift。在2017-2020年期間,Google 曾挖角 Swift 之父 Chris Lattner,加入研發AI的“Google Brain”團隊,嘗試以 Swift 改寫其人工智慧程式,結果創作出 Swift for TensorFlow,可惜這個計畫在2021年終止。
幸好,在Apple原廠積極投入人工智慧的努力之下,不但從硬體上優化,每顆Apple 設計的核心晶片都帶有「神經網路引擎」(Neural Engine),可加速人工智慧程式;在軟體上,也不斷擴增人工智慧相關框架與物件,令 Swift 也成為人工智慧相當合適的程式語言,並可充分享受硬體加速的優勢。
因此,第5單元將介紹如何用 Swift 設計人工智慧程式,課程理念仍與前四個單元一致:以高中程度為對象、採用 Swift Playgrounds 為實作開發環境、中文化命名、完整範例程式、盡量使用基礎語法。
具體來說,第5單元將學習 Apple 的人工智慧框架,包括 CoreML, Vision, Speech, NaturalLanguage 等,涵蓋人工智慧三個核心領域:「視覺、聽覺、語言」,課程大致包含以下應用:
- QR Code
- 電腦視覺
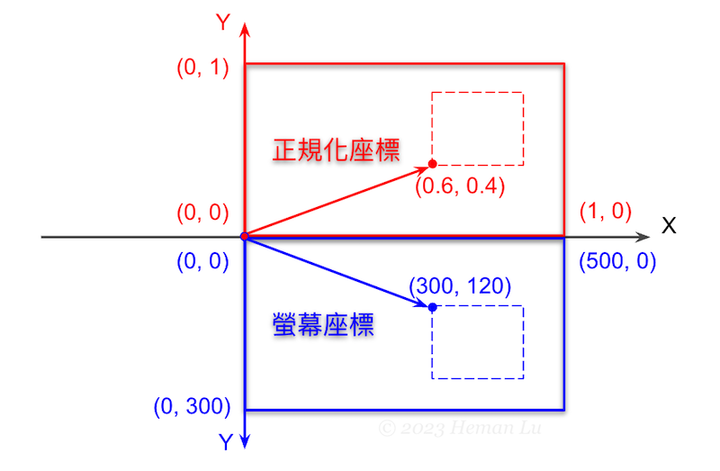
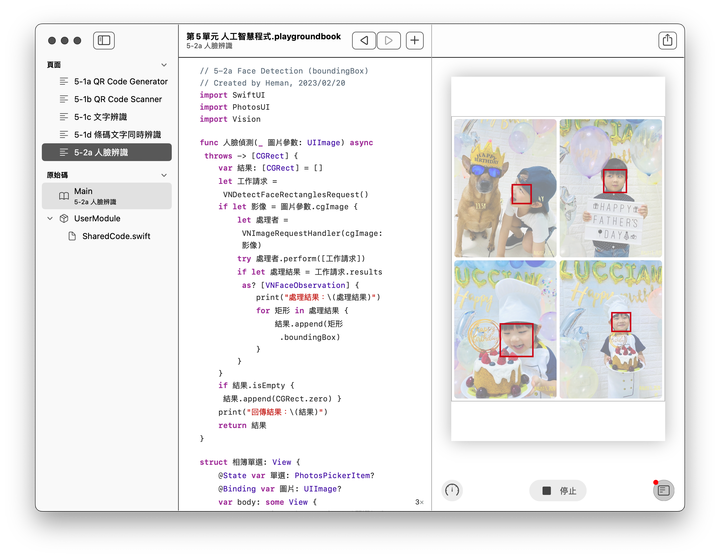
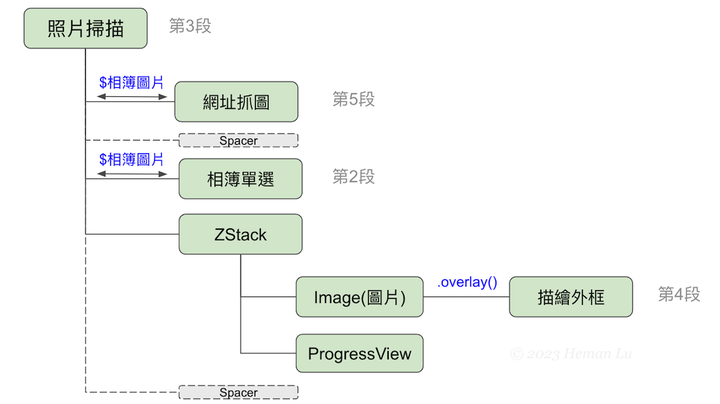
- 人臉辨識
- 物品辨識
- 語音辨識
- 自然語言
希望學習之後,能夠了解:
1. 如何動手實作人工智慧程式
2. 知道人工智慧擅長解決什麼問題
3. 日常生活哪些情境能運用人工智慧
學習路線
➤ 下載Swift Playgrounds App https://www.apple.com/tw/swift/playgrounds/
➤ 第1單元 Swift 程式語言基礎 https://www.mobile01.com/topicdetail.php?f=482&t=6402999
➤ 第2單元 SwiftUI 圖形介面基礎 https://www.mobile01.com/topicdetail.php?f=482&t=6424982
➤ 第3單元 Swift 網路程式基礎 https://www.mobile01.com/topicdetail.php?f=482&t=6453587
➤ 第4單元 SwiftUI 動畫與繪圖 https://www.mobile01.com/topicdetail.php?f=482&t=6555364
後續課程
➤ 第6單元 AR擴增實境與空間運算
💡 註解
- 艾倫.圖靈(Alan Turing)對現代電腦基本理論的貢獻非常大,全球電腦科學領域最高榮譽就命名為「圖靈獎(Turing Award)」,約翰.麥卡錫曾獲得1971年圖靈獎。艾倫.圖靈也是電影「模仿遊戲(The Imitation Game)」的故事主角。
- 圖靈的模仿遊戲-《創新者們》 - PanSci 泛科學
- 電腦首次通過圖靈測試,人工智慧大突破?艾倫.圖靈在1950年文章中曾預測「可能50年後才有程式能通過測試」,如今看來確實如此。
- 有趣的是,Swift 之父 Chris Lattner在2022年1月與一位Google Brain同事共同創辦一家人工智慧公司 Modular AI,並擔任執行長(CEO),全力投入人工智慧領域。
- 以iPhone 14 Pro所用的 Apple A16 晶片為例,裡面包含了6核心CPU、5核心GPU 以及高達16核心的神經網路引擎,可見Apple對人工智慧的重視。