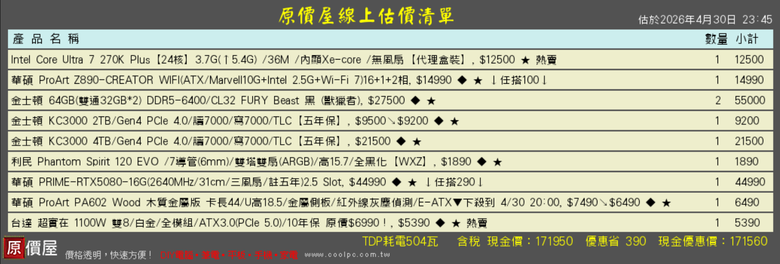
主機規格
1:CPU U9 285K
2:RTX 5080 VRAM 16G
3:RAM 128G
4:2T +4T PCIE 4.0
5: 主機板 具 10GbE網路,WIFI 7
6: 非遊戲機
因久未注意市情,請版上諸位前輩提供建議及參考規格


這年頭還有人異想天開用單卡train model, 是要跑回歸模型嗎
5080就算拿來finetune 很小model,也要降batch size, 慢到吐血, 然後還很難tune出好模型硬體太爛.
這預算真要搞, 就去找便宜cloud算力用租的
yungdab@excite.com wrote:
算了吧,
這年頭還有人異想天開用單卡train model, 是要跑回歸模型嗎
5080就算拿來finetune 很小model,也要降batch size, 慢到吐血, 然後還很難tune出好模型硬體太爛.
這預算真要搞, 就去找便宜cloud算力用租的
我同意你的說法,
現在要做出足夠擬真的影片,模型大小能輕易接近100GB,
16GB的顯示卡真的完全不夠看。
由於效能常卡在記憶體的關係,RTX 5080 和 Intel® Arc™ Pro B70 Graphics 32GB相比,
到底誰輸誰贏 ? 目前找不到直接比對的資料。
16GB的顯示卡拿去生成夠水準的文章都不一定足夠,
Arc™ Pro B70 Graphics 32GB 拿來生成文章比較保險。
eanck
eanck
steven2008 你可以寫信直接問intel,甚至可以請他們提供測試數據供你參考。
2026-05-01 11:52
針對 intel B70 GPU 性能評估
以下是針對各框架的相容性詳細評估:
1. PyTorch:原生支援 (XPU)
這是你最不需要擔心的部分。2026 年起,Intel 已經將大多數優化代碼併入 PyTorch 官方主線(Upstream)。
相容性: 優。
執行方式: 你不再需要安裝複雜的插件,直接使用 device = 'xpu' 即可調用 B70 顯卡。
優勢: 支援最新的 FP8 與 MXFP4 量化加速。對於你的 SSPS 或 SODS 系統,這意味著你可以直接跑 PyTorch 官方模型而無需修改代碼。
2. JAX / JIT:透過 OneAPI / PJRT
JAX 的相容性在 Intel 平台上主要依賴 OpenXLA 與 PJRT 插件。
相容性: 良(需手動配置)。
執行方式: 需安裝 intel-extension-for-tensorflow 所附帶的 JAX 插件。
JIT (Just-In-Time): 支援 jax.jit 編譯至 Intel GPU,但對於極少數針對 NVIDIA 寫死的 Triton Kernel 可能不支援。
現況: 2026 年的 Intel 驅動已能穩定支援 JAX 的矩陣運算,但在處理「自定義 Kernel (Pallas)」時,目前仍以 NVIDIA Hopper 架構最為完整。
3. CUDA 相容性:SYCLmatic 與 ZLUDA
這是最核心的問題:如果你手上的代碼是寫死 cuda() 怎麼辦?
解決方案:
SYCLmatic: Intel 官方提供的代碼轉譯工具,能將 90% 以上的 CUDA 代碼自動轉換為 C++/SYCL,讓 B70 執行。
ZLUDA (2026 版): 目前已有開源社群維護的 ZLUDA 版本,允許 Intel GPU 直接模擬 CUDA 環境 運行二進位檔案,雖然有效能損耗,但對於「懶人部署」非常有用。






























































































內文搜尋