

AMD GPU 技術與工程研發資深副總裁王啟尚 David Wang。
在本屆的 Computex 展中,AMD 除了消費端的 Ryzen 9000 系列處理器(請見:【Computex2024】AMD 推出 Ryzen 9000 系列處理器 透過 IPC 提升不僅效能更強更省電)以及 Ryzen AI 300 系列筆電處理器(請見:【Computex2024】AMD 推出 Ryzen AI 300 系列處理器 以目前最高 NPU AI 算力提供更多行動 AI 效能)之外,還針對 Data Center 資料中心以及邊緣運算部分,推出包括第五代 AMD EPYC CPU、MI325X GPU 以及 Versal AI Edge Series Gen 2 單晶片,打造結合 CPU/GPU/NPU,從雲端到邊緣,到終端產品的完整產業鏈,再加上 ROCm 開放軟體架構,可說是目前業界最完整的 AI 軟硬體平台。

AMD 在這次 Computex 也發表了第五代 EPYC 處理器,採用 Zen 5 架構提供最高 192 核心 384 執行緒配置。
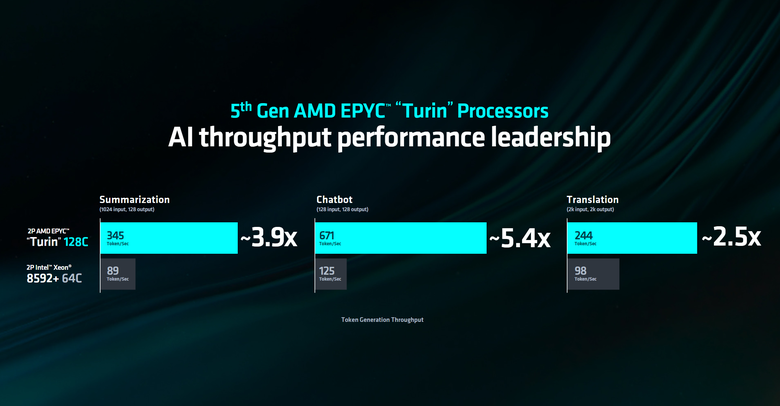
比起競爭對手 Intel 64 核心的 Xeon 8592c 處理器在整體 Throughtput 上面要領先許多。

在 GPU 部分則是有 Instinct MI325X,採用 HBM3E 次世代記憶體,具備 6TB/s 的頻寬。

另外也預告了下一代的 MI350 系列將在 2025 年登場的消息。

跟競爭對手 NVIDIA B200 相比在記憶體容量跟 AI 算力部分均有領先。

針對邊緣 AI 運算所推出的 Versal AI Edge Gen 2 FPGA 單晶片。
可以看出這次 AMD 發表的產品陣容相當豐富,而在 Keynote 活動過後,陳拔也應 AMD 邀請訪問了 AMD GPU 技術與工程研發資深副總裁王啟尚 David Wang,來談談這次 AMD 發表的整體產品線以及接下來的趨勢走向。
David 首先表示,AMD 這次最重要的,就是發表從雲端到邊緣到終端的完整產品,展現 AMD 從硬體面到軟體面對於 AI 的各項應用都是準備好的,像是在 Data Center 資料中心部分,以 Instinct MI 系列 GPU 來說,AMD 的產品規劃從每隔一年,加速到每一年都有新一代的產品推出。而在邊緣 FPGA(Versal AI Edge Gen 2) 的部分,裡面會有 AI 引擎的配置。

Instinct MI 系列的 GPU 更新頻率由每隔一年改為每一年都有新品推出(產品經理壓力真大)。

結合了邏輯晶片、AI 加速引擎以及高性能 CPU 的 Versal AI Edge Gen 2 FPGA 單晶片。
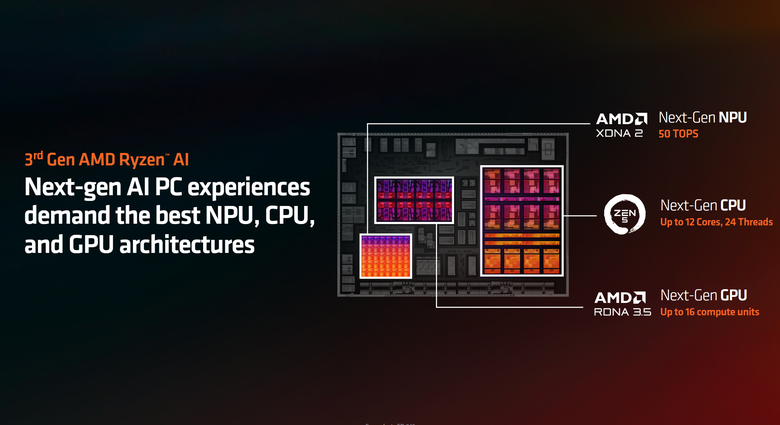
而同樣的 AI 引擎配置也放在消費端的 AI PC 上面,最新的 Ryzen AI 300(Strix Point) 處理器可以說是在業界裡 NPU 性能最強的產品,還有最新發表的 Zen 5 處理器。從 CPU、GPU 到 NPU,AMD 在這次 Computex 做了一個很大的宣布。另外在產品像是功耗的細節部分,這次的 Computex 展上面並沒有詳細揭露,要等到 7 月份才會有更細節的規格與產品資訊可以講。不過 David 也表示,AMD 一向的傳統就是具備傑出的能效比,這部分的規格之後將會有更詳細的訊息可以揭露,但時間點還沒到。

David 表示 Ryzen AI 300 處理器具備目前最高 50 TOPS 的 NPU 配置。
首先陳拔詢問有關於 CPU+GPU+NPU AI 算力整合的概念,AMD 對於這部分有甚麼看法。David 針對這部分,首先表示 AI 對 AMD 來說不管在哪個產品線,都變成很重要的應用。即便是在傳統上或是一般人認為不是 AI 晶片的 CPU,但實際上在絕大部分的企業或是終端使用者的使用情境中,有很多的 AI 應用仍然是在 CPU 上面處理就是了,加上 AMD 新一代的 Zen 5 CPU 對於 AVX 512 指令級的加速,對於一些通用運算的效能,以及對 AI 加速的函式庫應用都有相當好的效能表現,Zen 5 CPU 其實是可以作為一個好的 AI 運算的引擎,AMD 董事長暨執行長蘇姿丰博士在 Keynote 中也有提到這點。

雖然圖裡顯示是 Data Center 用的 EPYC 處理器,不過概念是差不多的,在 CPU 端是通用目的的運算,另一端 GPU 的則是用來進行 AI 訓練或是大型語言模型的推論(當然在消費端還有遊戲)。而在中間就是混和了通用運算以及比較小型模型 AI 的推論。
而 AMD 的 CPU 除了可以進行通用運算之外,也能做出比較小型的推論,在效能表現部分也相當不錯,而運算需求比較重的推論/訓練部分就是在 GPU 端執行,這個概念不僅在 Data Center 端,到了邊緣 Edge FPGA 單晶片或是個人終端的 Ryzen 處理器上都具備,而 AMD 在所開發的 AI 功能與應用,在全產品線上也會落實。

目前只有 AMD 的 CPU 可以兼顧通用運算與小 AI 模型的推論效能需求。
David 另外也強調在軟體的部分,AMD 未來的願景是可以透過共通的方式,可以依照客戶的需求,透過編譯的方式讓模型可以跑在不同的硬體上,像是客戶有 CPU,就用 CPU 跑、有 GPU 就用 GPU 跑,有 NPU 就讓 NPU 跑,或是如果客戶系統三個都有的話,還透過不同網路 Layer 進行分配,達到 1+1+1 大於 3 的效果,這是 AMD 未來的願景跟策略。

AMD 希望未來可以透過開放的共通平台,讓 AI 模型可以在不同的架構間快速轉換運作。
另外 David 也表示,每一個 AI 引擎都有不同的使用場景,像是 CPU 的通用運算,其實很多 AI 應用也有一大部分是通用運算的部分,像是整理資料的預先處理(Pre Processing),以及 AI 運算後的後處理 Post Processing 等等,都需要通用運算的 CPU 來處理,CPU 的角色仍然重要。
而在 GPU 跟 NPU 的部分,David 表示應該說因為所有的 AI 模型都是用 GPU 訓練出來的,所以在 Time to Market 導入市場速度的角度來看,所以 GPU 適用的 AI 模型推出最快,直接 Compile 出來就可以用了(陳拔:所以現在 NVIDIA 在目前比較有優勢)。但是這不會是最佳功耗的方案。如果說是要針對功耗進行最佳化,AI 模型就需要針對 NPU 再進行調整,這個動作在目前仍然需要花一些時間跟成本,AI 模型開發廠商在這部分的腳步還沒那麼快。
另外在精度部分,目前 NPU 的運算精度還是沒有如 GPU 高,所以在運行 AI 運算的結果上可能會不如預期,不過這就是 AI 運算上的 Trade-Off,要高精度高算力,就需要用 GPU ,帶來比較高的耗電,而在 NPU 則是反之,所以在 AMD 目前這個 CPU+GPU+NPU 的組合,就是結合了通用運算需求/最快運用 GPU/兼顧遊戲需求以及低功耗 AI 運算的解法,而 AMD 目前在這三個部分都算做的還不錯。

當然在未來 AMD 希望透過多層的 Graph Compile 網路編譯器,可以根據系統裡有哪些 AI 引擎,將不同的運算模型以不同的網路曾丟給不同的運算引擎(CPU/GPU/NPU),這樣的話就可以用 CPU+GPU+NPU 的總合算力來看待 AI 效能這件事。不過這部分的技術進展還沒那麼快,目前仍是將全部的工作負載放在同一個編譯器裡頭去執行,我們能做的是讓整個模型變得更成熟,讓它可以很簡單的進行編譯最佳化,但這也需要更多人力資源下去調整就是了。
所以對應到消費端,像是先前微軟公布的 Copilot+PC 上面,微軟定義這個功能要一直開啟,所以功耗不能太高,像是 Recall 這項功能就是需要一直在運作的,所以功耗就要很低, 所以就要丟給低功耗的 NPU 來做。從這個角度來看,AMD 今天宣布的 50 TOPS 是領先業界,在微軟的作業系統的優化來說是最重要的重點,單純的 A+B+C 的數字以目前的 AI 效能評估來說仍然不太適用。
至於跟競爭對手相比,AMD 目前的優勢在哪?David 表示每一家廠商都有其擅長的地方, AMD 目前就是 CPU、GPU 跟 NPU 都做得很好,相當均衡,Intel 相對於在 GPU 比較弱,NVIDIA 在 PC 端沒有 CPU,所以 AMD 會確保這三個面向持續的發展保持優勢。
另外一個 AMD 的主要特色就是軟體都採用開源策略,我們可以跟合作夥伴一起創新,這是一個比較開放的生態鏈,當然 NVIDIA 在 AI 部分起步較早,但 AMD 希望在透過開放架構的策略,不管在軟體跟硬體部分都可以很快趕上,像是在資料中心的 UA Link 聯盟(對比 NV Link),透過Broadcom 或是 Cisco 這樣的合作夥伴,可以打造出效能很棒的 Switch 機器,另外在合作夥伴內也包括數據中心廠商,他們也高興有這樣的開放標準,不用擔心被鎖定在一個專有的解決方案。

AMD 與合作夥伴推出的 Ultra Accelerator Link 架構技術。
另外要跟競爭對手做出差異化,David 表示關鍵就是要把每一件事情做好,以 AMD 來說就是把包含 CPU、GPU、NPU 以及軟體在內的產品持續改進。另外一點就是透過 AMD 開放的企業文化,以及與客戶/合作夥伴的交流來持續提升產品競爭力。AMD 拉了產業裡面一些夥伴來一起合作競爭,像是 Intel 也加入了 UA Link 這個聯盟,就是一個很好的例子。

最後問到有一點技術性的部分,因為這次 Ryzen AI 300(Strix Point)處理器裡面將 GPU 升級到 RDNA 3.5,在這部分跟先前的 RDNA 3 有甚麼不同。David 表示雖然這個會在 7 月份有更詳細的資訊透露,不過在大方向上, RDNA 3.5 主要是針對這次的 Ryzen AI 300(Strix Point)處理器進行最佳化,包括將 CU 運算單元數量由 12 個增加到 16 個,在 APU 角度來看是相當大的性能提升,可以提升遊戲與工作負載上的表現。另外針對未來的 RDNA 4 架構,更強的光線追蹤性能以及如何增強 AI 效能與體驗(包括畫質與性能提升)都仍然是發展重點,不過更詳細的細節,就等到 7 月份再來說了。

 AI是趨勢
AI是趨勢

































































































