

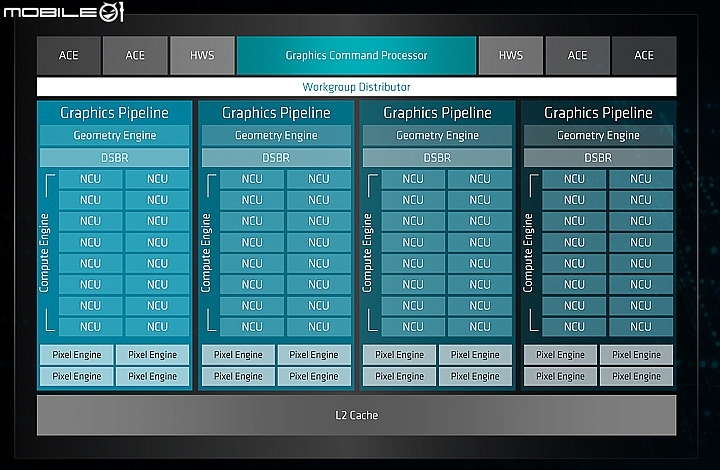
AMD這次針對深度學習運算推出加速卡一共有Radeon Instinct MI60與MI50兩款,其架構設計基本上都是採用了AMD Radeon VEGA架構設計,其中比較不同的地方就是提升了晶片製程以及記憶體容量和頻寬。
底下是官方提供的規格比較表給大家做個參考。
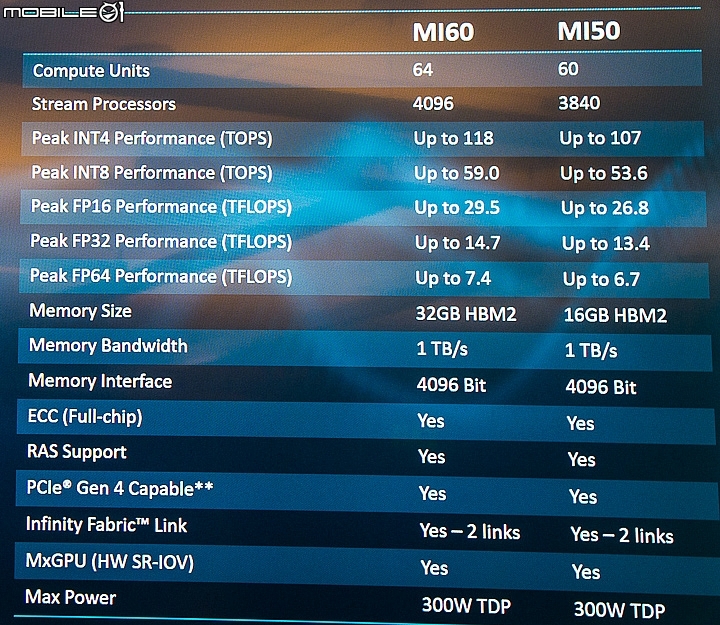
另外,這次的Radeon Instinct MI60與MI50運算加速卡中的繪圖晶片快取記憶體也都有支援ECC糾錯功能,提供用戶更穩定的精度運算效能表現。

從官方提供的測試數據來看,AMD Radeon Instinct MI60在TensorFlow FP32運算應用方面的表現比起上一代的MI25大約都有著25~50%以上的提升幅度,而且這次2~8 GPUs串接的效率也明顯提升許多。

就官方提供的資料來看,AMD Radeon Instinct MI60相較於對手Tesla V100的深度學習運算的效能表現可以算是不相上下,而且AMD Radeon Instinct MI60由於製程的提升也讓晶片面積變得更小,因此也讓用戶有更彈性的空間配置。


為了讓有多卡運算需求的用戶有更高效率運算效能,AMD Radeon Instinct MI60與MI50還加入了Infinity Fabric Link功能,主要特色不僅能夠讓GPU之間溝通的頻寬達到200GB/s,亦可共享每個加速卡上的記憶體容量來達到更好的運算效能表現。

AMD Radeon Instinct MI60與MI50加速卡上都有設置了Infinity Fabric Link接頭,可透過專屬的橋接器連結各個加速卡。

針對一些虛擬化硬體設備需求,AMD Radeon Instinct加速卡也能夠支援1/2/4/8個GPU的配置,讓虛擬化平台有更彈性的硬體部署配置。

首款採用7nm製程的AMD Radeon Instinct MI60加速運算卡預計這一季就會正式出貨,而下一代的MI加速卡也已經持續開發中,預計2020年就會正式問世。






























































































