這次ATI發表會上除了RV670本身的發表之外,還偷偷夾雜了一個蠻讓人吃驚的real time demo:OTOY real time 3D rendering。
雖然只是影片,不像日本和美國的發表會有即時run出相當高品質的3D動畫,不過震撼力仍然非凡。
有興趣的請參考OTOY的網站。
以下為與AMD繪圖產品事業群資深總裁David Wang的專訪。
--DX10的重頭戲
Q: 我想請問關於剛剛在發表會最後提到的電影級動畫及時繪製的技術,tessellator是一個sub-division的技術,而且沒有辦法從CPU放到GPU,那該如何把這個巨大的模型(一億個多邊形!!)放進GPU呢?
A: 其實這個100M多邊形的模型其實是不存在的,實際上可能只有10M(一千萬個)多邊形左右,這個規模你就可以從CPU透過PCIe、 HyperTransport放到GPU。
但是在這個10M的模型被GPU讀進去之後,在繪製的過程會透過tessellation unit把原有的模型做更細緻的切割。

原始的模型是每11~38小時一個frame,但是RV670透過Tessellator可以消化這麼大量的資料,進而達到real time?!
Q: 所以您的意思是說,tessellation unit等於可以把一般CG動畫在CPU上執行的sub-division shader直接在GPU上執行了?
A: 是的,這其實關係到兩個部分,一個是performance,因為這麼大的模型你沒有辦法在CPU上直接run。第二個其實是做model的人力問題, artist其實沒辦法靠人力做出這麼精細的模型,很多細部的部分都是用工具產生的。所以sub-division這個技術其實是相當先進而且相當有用的,XBOX360也支援這個技術,很多遊戲廠商都很喜歡。

Q: Tessellation Unit有個問題是說,根據先前humus的說法,不論是XBOX360的tessellation unit(可以生成1~16個vertex),或者是DirectX10的GS spec(0~1024個vertex),甚至是R600號稱如果不受DX10 spec限制的話,優勢會更大....但是最大一定會受到Triangle setup engine的限制對吧?
A: tessellation unit本身可以產生更多,但是的確是會受限於於triangle setup engine的性能。
Q: 所以它本身其實也超過DX10規定的(0~1024個)vertex的生成能力嘍?
A: 這點我可能要和我們的team稍微確認一下,因為我沒有碰觸到實作細節.....
--CrossFire X
Q: 過去ATI在R300發表的時候,曾經提到過R300能夠串連到256顆GPU,好像是能以編號來分辨GPU並且將每個quad分別並列的supertile模式。
A: 這個是理論上的規格啦,雖然硬體有這個功能,但是實際上因為PCIe等I/O的限制,實在很難達到這個數字,所以我們短期內的設計方向並沒有像CELL那樣打算接到幾百上千顆的規模。
Q: 關於PCIe 2.0,你們剛才在簡報裡面有提到遊戲會因為PCIe 2.0提升性能,會有15~20%,但是先前有其他廠商做過一些研究,他們發現其實現在CPU與GPU之間傳輸vertex的數量已經非常小了,因為 GPU包辦了Vertex shader之後,GPU已經會在自己的記憶體存完整的data,CPU只負責傳送index到GPU上。
(E:有點像是整個人雖然在跑動,但是CPU送給GPU的其實只有這個人形的重心位置變化,剩下構成人型的每個vertex,都由GPU來負責運算各個頂點"加上重心位置變化"後的狀況)
在這個前提下,其實PCIe的使用率只有幾%而已。那為什麼會有那麼大的幫助呢?
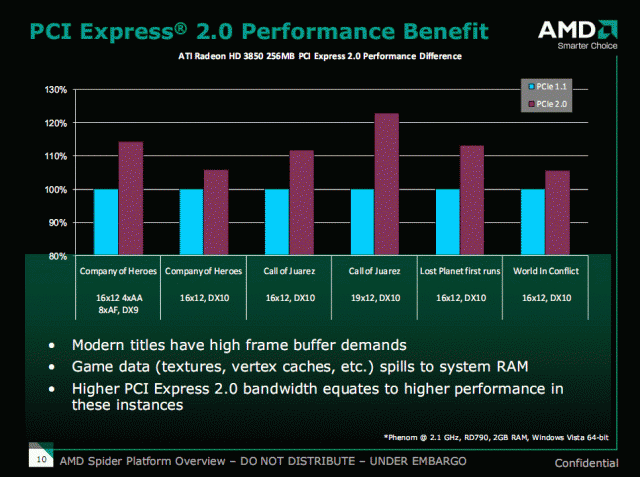
A: 我覺得有個原因是因為Texture。因為texture以前很可能是手繪,現在的texture產生過程則可能甚至是掃描或是照相而已。所以如果GPU上的記憶體不夠用的話,就會需要從主記憶體透過PCIe來傳輸到GPU上。
另外一個問題是,如果硬體沒有tessellator的話,那麼有些model並不完全儲存在GPU上,你還是得從主記憶體作DMA傳輸給GPU。所以主要的問題還是texture。
Q: 那麼,不是提高GPU的記憶體容量比較有效嗎?
A: 當然增加frame buffer memory的話你材質就可以全部放進去不必paging,但是這樣一來成本就高了。二來這樣成長也會有一個界限,因為增加幾乎都是倍數(如256增加到 512),這已經是個非常大的負擔了,所以PCIe 2.0的優勢會慢慢顯現出來。
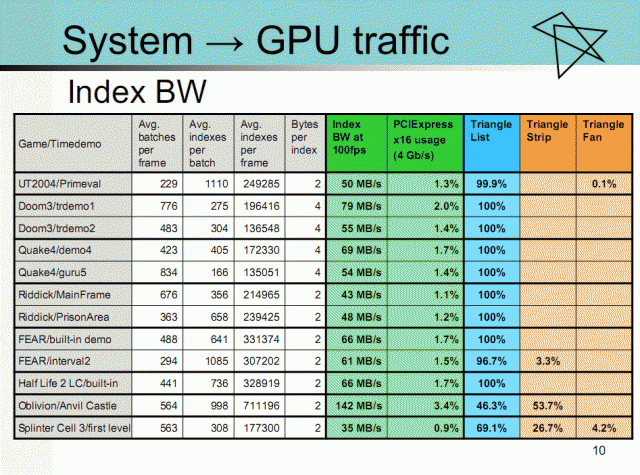
參考資料: http://iiswc.org/iiswc2006/IISWC2006P1.2.pdf
Q: 所以其實記憶體容量真的開始成為瓶頸了,那麼這邊有個相關聯的問題是CrossFire。我們都知道CrossFire的狀態下每張卡都必須存一份材質....NVIDIA的7950GX2也有這個問題。那你們的3870X2,會實作NUMA的結構嗎?
A: 呃.... 有NUMA這會好一點沒錯,但是很難做到整個系統裡面全部的材質都沒有重複。因為這可能會造成這幾張卡之間各自的材質得要互相傳來傳去。這反而可能會讓效率變差。所以我們希望多晶片下,單卡本身的記憶體能夠加倍,但是跨卡的話就不容易。長期的方向會朝NUMA走。
--RV670的體質
Q: 想請問一下,RV670的AA的resolve還是由shader來執行嗎?
A: 都可以,它有兩個mode,一個是由硬體本身,另一個是CFAA,在剛剛我們有個demo(GI)裡面可以看到有許多小球的邊緣,那個就是利用CFAA是交給shader處理。我們認為這個做法可以被DX10.1所接受,是因為它有其優勢存在,會是未來的趨勢。
大家可以看得出來AMD的硬體之間所算出來的畫面彼此之間差不多,而NVIDIA的硬體也差不多,就是因為各個廠商有各自的演算法;用CFAA的話developer就可以用自己的方式增加一些AA的演算法上去,表現出不同。
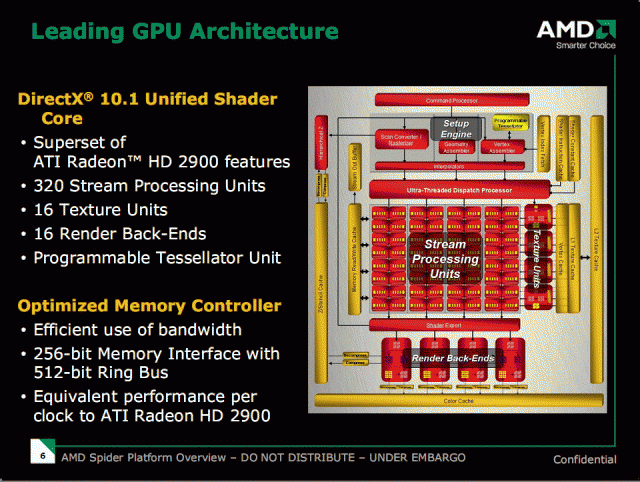
Q: R600大約有700M電晶體,RV670則約666M個,但是卻追加了UVD之類的功能,那少掉的電晶體是哪些部分?會帶來什麼衝擊呢?
A: 我們在memory controller上作了一些optimization,從512bit減到256bit,而且我們也把記憶體的速度提升了很多,所以雖然bus寬度減小,但是性能上的衝擊應該不會很大。
--DX10.1的各種新增功能
Q: 另外一個問題是關於MSAA depth readback這個功能。
A: 這是因為一種繪圖技巧叫做deferred rendering(間接繪製),這個方式指的是render完成後先不顯示出來,先render到一些暫存區,所以你會有multi-sample的sub-pixel,也會有z-sample的sub-pixel,然後可以再讀回去運算。
支援msaa depth readback的話,會對deferred rendering幫助很大,使用這個技巧的話比較不會被硬體的頻寬限制住。
Q: 其實就我所知,這些功能其實在DirectX10之前,你們的硬體就支援了,比方說XBOX360。
A: 詳情其實我不太清楚....不過CFAA這些東西的話我們是蠻早就支援了。
Q: 類似R420支援的Temporal AA嗎?
A: 是啊。那你講的沒錯,我們支援得有比較早。
Q: 也就是說,通常這一代的GPU都會包含上一代的功能,比方說DX10.1就會包含DX10的功能,也會包含DX9的功能。
A: 嗯,這一代的功能通常是上一代的superset。
Q: 所以正常來說DX11會包含DX10.1的功能?
A: 是的,一般來說應該都會。即使DX11最後不支援DX10.1的功能,我們還是會提供回朔相容的設計。不然的話如果DX11不能玩DX10的遊戲,那可能就會很糟糕。
Q: 所以說關於DX10.1的這些功能,比方說cube map array或者是msaa depth readback,還有MSAA強制的一些要求。尤其是把MSAA規定設計得這麼細,會不會有替ATI量身打造規格的疑慮呢?
A: 喔,不會,沒這回事。其實這是Microsoft在發展過程的時候發現,developer在設計遊戲的過程中,會因為MSAA本身是個相當耗損資源的功能,如果遊戲沒有設計好就使用MSAA的話很容易帶來很大的效能衝擊;但是完全不使用MSAA的話對畫面品質也會有負面影響,結果Microsoft作出的結論是,如果將GPU的性能與功能的最低標準baseline提高的話,developer就可以比較積極地使用這些功能。
這個標準應該是會讓遊戲規則變得比較公平才是,否則Microsoft這麼大,應該沒有必要遷就ATI吧!

ATI的Global illumination demo。兩手拿的其實是吹風機....XD
Q: 可是你們的TAA當初有個問題是必須render到120fps才有辦法因為視覺暫留來出現TAA的效果,而這在最近的遊戲幾乎是不太可能的,這樣的話有必要把這個功能(custom filter)強制放到DX10.1裡面嗎?
A: custom filter這個功能其實不完全是為了TAA,它能夠提供更複雜更靈活的filter,如果考慮性能的話,其實你沒有辦法對畫面的每個角落都用CFAA,那樣會太慢;但是這是提供給designer的選項,讓他們可以在需要的地方使用。我們在GI的demo裡面有展示過自動搜尋邊緣的filter,它可以顯著提供更好的品質。不然有五千個球散亂地堆在一起,球與球交錯遮掩、還有背景也被球,傳統的AA下那些邊緣不會很好看。
不過TAA這個功能你講的沒錯,雖然GPU性能有幾乎兩倍的改善,但是遊戲也會更為複雜,所以你在新的遊戲上,TAA的適合度就沒那麼高。
Q: 所以說主推的方向就變成custom filter?
A: 這都是給developer的選擇啦。上面提到的是一些特殊的狀況,所以我們透過DX10.1提供這些功能來應付這些需求。
Q: 可是一般在movie quality的狀況下,其實如果遇到這種狀況,通常是用更高倍率的AA來解決,比如說32x或是64x。
A: 和我們合作的公司基本上也是在try啦....他們最終目的也不是一定要做到render一個movie都能夠real time,因為你如果能達到同樣的品質,那麼本來CPU要算十幾個小時的東西,你現在可以幾分鐘搞定,時間效率賺了幾百倍,這樣對動畫市場來說就很賺了。
對遊戲來說,我可能可以在不同的場景用不同的filter,比方說現在這個場景是磚牆,下一個場景是樹林,就會各自需要不同的filter,來達到最好的 AA品質,而developer可以準備五個甚至很更多的filter來配合需求;但是其實同樣都是一個邊緣偵測的shader就可以了,原理都是數位信 號處理。
(E:不過老實說,這樣看起來他們想說CFAA能夠改善效率與品質,成為達到movie quality的關鍵;但現在就算是NVIDIA的16x CSAA也不會真的造成很大的效率低落)
Q: 可是這樣CFAA的問題就出現了,剛剛說custom filter是可以由game developer來決定,可是這是不是代表developer要去特別去設計這些filter,而造成開發上的效率問題呢?會有研究的陣痛期吧?
比方說像當年R520的HDR+AA,它有blending但是Texture Unit沒有fp filtering,結果就變成遊戲畫面初期有一些不相容的狀況,結果CFAA可能也要變成要求遊戲Developer去做一些底層的研究。
但是競爭者則是直接在硬體上做一個很強大的AA性能來解決所有的問題,那麼相比之下CFAA還會有人用嗎?
A: 但是DX10.1的功能也不只是CFAA,還有剛剛講的Global Illumination使用到的indexed cube maps,這都是相當powerful的功能。
developer 可以從這些功能來衡量說我到底要不要支援DX10.1,我想你說的沒錯,如果只有CFAA這個feature的話,DX10.1並不是很有吸引力;但是如果加上Global illumination等所有DX10.1的功能來看的話,我覺得就相當相當有吸引力。
(E: 我是覺得David迴避了一個問題:這邊會有一些設計上的取捨,這邊提到R600族系其實有點依賴developer使用CFAA,所以一般狀況AA性能就不是那麼強勢,RV670也會遇到類似的問題。
那麼如果NVIDIA推出G92一半大小 or G84兩倍大的晶片、記憶體介面卻和ROP相去不多的版本呢?
會不會即使在DX10.1底下、developer沒有善加利用CFAA的狀況下,這樣的晶片還是可以和RV670對抗?
畢竟G92其實是記憶體頻寬嚴重限制性能的設計啊)
Q: 根據你們的roadmap,DX10.1正式發表似乎是2008年Q1,那遊戲是要在之後才用得到對吧?
A: 不過我們檯面下還是有一些合作還不能講啦。不過同樣的道理,當初NVIDIA發表G80是在DX10正式發表前六個月,這也是同樣的道理。
總之API推出到遊戲推出總是有空窗期,但是我相信DX10.1會是DX11推出之前最主要的一個major step,我想到DX11還很久。
(E:不過也有廠商都在2006年中就拿到G80開始做遊戲啦....?)
Q: 意思是說DX10.1可以撐很久嗎。
A: 就像當年的Shader Model 3.0,NVIDIA推出得很快,就做得很糟糕啊。
SM3最重要的功能是dynamic flow control,這個功能能讓GPU像CPU一樣做比較靈活的條件判斷,這部分NVIDIA做得很差;我們等得比較久,就做得很好,而且等我們進去的時候,支援的遊戲也開始出來了。
所以API剛出來的時候都需要一點時間來catch up,重點是你有沒有把新的API的精神抓住,把支援的硬體做好,像當年SM3是Dynamic flow control,DX10.1是CFAA和indexed cube map。
Q: R500真的是非常強調Dynamic flow control,不過前面有提到DX10會包含DX9的功能,所以G80推出的時候也剛好catch up這個dynamic flow control的需求。
A: 是的,G80推出的時候就有把他們先前的缺點修掉。
Q: 先前Dave Orton曾經說過不知道NVIDIA怎麼把SM3(用那個大小)做出來的,現在你們知道其實NVIDIA是犧牲掉了動態條件分支。
A: 這個是SM3的精神所在,所以我覺得他們做得很不好
Q: 但是他們的銷售量顯然很好....這你們會不會覺得很....
A: 呃,是啊,不過資訊產業總是這樣嘛。
--ATI的經營政策面
Q: 我們回到XBOX360上好了,最近這段時間我們可以知道,XBOX360因為有很強大的vertex performance,有具備tessellator,在大部分狀況的表現都超過PS3。
那你們是不是放了很多精神在console上,結果變成PC市場只好用很像的結構來做R600;結果NVIDIA在PS3上其實用的是很現成的東西,但是在G80上就做了很大的step forword....有點PS3輸了不關我們的事那種感覺。
A: well.... PS3在繪圖上面有不小的瓶頸,CELL似乎有50%的horsepower在作一些GPU該做的事情,比方說clipping之類的。
我想對我們來說360的確花了很多時間,不過360畢竟不是DX10而是DX9+,只有部分的DX10功能。所以我想R600時間會花的久還是因為DX10本身,這畢竟是我們第一次做DX10,所有的東西都是新的。
不知道你有沒有印象,在DX10剛推出的時候,我們的Driver是最穩定的。NVIDIA雖然宣稱有Vista Driver,但是很爛。
所以我們當初是把東西都做到好才推出,OS、Driver都,時間上就慢人一步了。
(E: 我是覺得R600會失敗的原因不只是晚推出,還有性能啦....)
Q: 所以你們覺得R600系列會失敗主要是因為等ready之後才推出而造成time to market的問題?
A: 我覺得這絕對是一個原因之一。
所以現在在DX10.1,我們認為這是一個major step的關係,所以這回3800series會是一個完整的family,明年一月的時候我們會和高階一起發表DX10.1的低階。
然後就可以做到top-to-bottom完整的產品線。
Q: 所以你們會覺得360拖累你們嗎?畢竟這是一個很customize的產品,會不會分走很多開發上的資源?
A: 我覺得不會耶,畢竟它是Unified Shader這個新架構的驗證,還有讓developer可以習慣tessellator之類的新功能,這些對後面的HD2000、HD3000都有受惠。
而且我們還有幫Wii做硬體,這一個市場我們佔有率很高,就有不少的獲利;反觀你看PS3賣得差,NVIDIA就沒什麼好處。
所以game console一做就是吃五年,GPU可能半年九個月就換代了,我覺得相較之下是一個回饋很高的市場。
因為他每台機器你都可以收權利金啊,你後面就沒有cost了。
Q: 不是聽說XBOX360的IP是賣斷的?你們還有因為他們主機賣得更多而獲利嗎?
A: 他是買斷沒錯啦,但是我們還是有一些比例的回饋金。Wii和360都有權利金的。
Q: 所以你們還會繼續做customize design嘍?
A: 不只這樣,我們現在比以前更有力的一點,是我們現在有從CPU、GPU到chipset完整的產品線,所以我們現在可以做整個系統,你可看到市場上只有我們有辦法做這種程度的整合。
Q: 比如說fusion之類的...
A: 嗯,我覺得因為AMD ATI合併的關係,今年是陣痛期,你可以看到市場表現沒那麼好;但是我相信明年的時候market share會反過來。
就我所知我們在desktop OEM明年一定可以回到50%,而notebook一定會超過50%到60~70%,回到我們過去的水準。
我們ATI比較弱的是通路的部分,NVIDIA在這方面的marketing和support真的都非常好,但是RV670就是要專打他這個地方,就像打蛇要打七寸一樣,NVIDIA過去獲利最高的就是這部分。
所以他們才急啦,才要把G92這麼大的die下放到這個市場來和我們競爭,那是18x18的die耶,我們才14x14左右而已,根本是不同階層的產品。
一個wafer只能切多少die,良率能多高?你可以去北美查查看G92的供貨,買不到多少量的。
我們希望670可以在聖誕節檔期大量鋪貨,因為他的die小很多,每片wafer能切的量就會多,才能真正滿足這個主流市場。
目標就是200美元這個市場,pro(3850)是200稍低、XT(3870)是200稍高,剛好切到8800GT的250美金下面的市場。
所以他當然就很緊張啊。以前ATI不做這個市場,要就是highend,不然就是630和610這種OEM需求。
現在670正好就是針對DIY市場的產品,所以現在起我們會專門往這個方向來打。希望可以把market share拉近一些。
畢竟NVIDIA在這一塊真的是很強勢啦....
Q: 畢竟一般人可能覺得"喔,RV670被8800GT比下去了"
A: 所以我前面才會說我們的cost performance的部分,希望你們在寫評論的時候能夠注意一下,那是個完全不同等級的die和產品,8800GT其實不應該是賣這個價錢的。
但是我們希望feature set能比較強,那時候我在北京,講的則是1499rmb這個市場,也是199美金的。
Q: 所以3850的定位等於是1950pro就是了?
A: 等你們拿到Demo卡的時候,你們大概就會知道確切的價錢啦,不過原則上這兩個產品就是200美元上下就是了。
有些市場就是一定要那麼低價人家才會買,超過預算就不會考慮;有些市場就會變成性價比會影響比較大。
有些人就是超過200美元就不會買,但是3850雖然價錢低,性能並不見得會比較差,它還是有8800GT約80%的性能啊,這很驚人。
這是個trade-off,我是希望大家可以用自己的錢包來衡量看看,你可以用這些錢買到這個等級的性能。這點我覺得很重要。
如果是DIY玩家你以後還可以考慮CrossFire,看主機板的擴充性,要裝到兩片、三片甚至四片都沒關係。
因為他夠便宜,你也可以玩多螢幕,比方說fight simulation X;你也可以用多螢幕環境來改善你的工作效率,面前擺多個螢幕來容納更多的視窗,這都是很有意思的。
----心得與結論。
雖然上面有些東西很想吐槽,不過不能否定其實RV670是個相當有競爭力的產品。
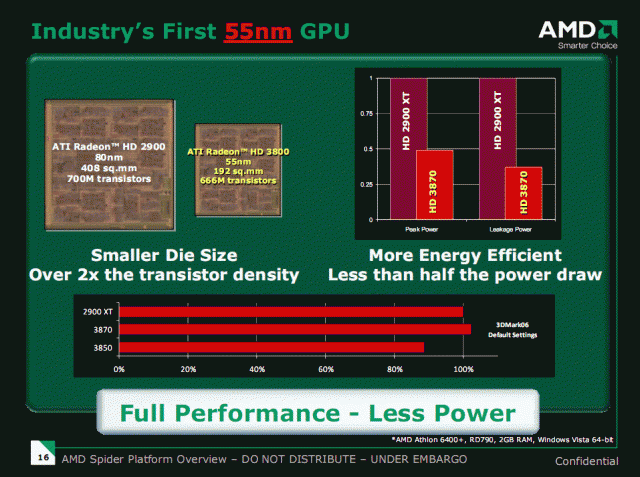
其實從die size這點就可以看到一個非常有趣的部分:這和NVIDIA在G70/G71的時候所面臨的狀況是正好相反的。
當年的G71 和 R580 的die size大約是196 vs 352、現在則是RV670和G92相比大約是192 vs 330。
而且在雙方幾乎均為較大的記憶體界面縮小為主流的256bit的同時,
R600往RV670是從408mm^2縮小為192mm^2,電晶體數量從700M縮小為666M。
G80 往 G92則是從484mm^2縮小為320mm^2、電晶體數量從681M增加為754M。
當然RV670採用55nm製程、G92採用65nm製程是造成上述的狀況的主因之一,55nm的報價必然會稍高於65nm,這點是毫無疑問,不然TSMC就不必推出這麼一個製程來賺錢了(笑)。
不過當然不會差太多,至少不可能像45nm那麼貴嘍。
考慮die size以及晶圓報價等等的因素,RV670的報價應該只有G92的2/3前後,考慮這點的話,RV670目前的性能表現是非常驚人的。
只是晶片本身雖然報價2/3,但是對板卡廠來說,最大的成本應該是記憶體,其次才是GPU以及PCB的layout負擔。
所以基本上這個差距還會再被其他的元件報價稀釋,最後消費者買到的價錢差距會更接近:以目前來說,很可能會遇上"3870的前多花一千多塊錢,就會有8800GT可買"的狀況。
這我想會讓很多朋友傷上一陣子的腦筋。
所以RV670的價值在哪邊?一個是良好的性價比,一如上述;第二點是DX10.1的功能與未來性,這點在下面做一些解說。
DX10.1在ATI的規劃裡面主要有兩個重點:CFAA,以及real time global illumination。
ATI提供的demo 以 indexed cube map (or cube map array)為光源處理的主幹,使用deferred rendering的手法,搭配msaa depth readback以啟動AA,來達成全場光源的互動。
從會場實際看到的狀況來說,在房間地面上五千個乒乓球除了受到物理運算控制之外,也都有受到環境光源的影響,效果相當不錯。
不過只有這個方法嗎?這倒未必。
我們可以參閱一下Crytek在Crysis(CryEngine2)裡面使用的Global illumination手法:
參考資料:http://delivery.acm.org/10.1145/1290000/1281671/p97-mittring.pdf

在Crysis內,Crtyek選擇的GI技巧其實是一個相對來說比較簡單的技術:Ambient Occlusion。
有用過3DSMAX的朋友應該會記得skylight這個plug-in,基本上就是同樣的技巧。
這個技術每個texel只需要一個scalar的關係,相對一堆GI的手法來說是比較簡單的。
實際建立的過程也只需要一個texel和occlusion value之故。

Screen Space Ambient Occlusion,是Crytek在引擎研究過程中無意產生的技術,只需要從Z-buffer中就可以取得足夠準確的光源資料。

效果,其實與上面ATI的demo效果很接近了。而且這是已經上市的遊戲採用的技術。
事實上,Realtime Global illumination這個領域相當新,有很多新的技巧出爐,可以說是八仙過海,各顯神通。
DX10.1裡面主推的indexed cube map算是其中一種方式。
當然我們如果以實作的觀點來看,DX10把TMU整個升級成indexable,並且給了一個名字叫做Texture Array。
而Cube Map已經是DX7時代就支援的東西,沒有跟著一起雞犬升天其實是相當怪的事情....
G80早期的OpenGL extension載明"目前不支援",其實也是讓人懷疑後續會不會加上去。(至少我現在很想測看看G92支不支援)
但是在這些技術之後,真正讓人在意的事情是:
因為有RV670的俗又大碗,所以我們現在看得到跟著俗又大碗的8800GT。
而消費者在意的,其實正是這一點罷了。





























































































