

在看過架構中針對 CPU、GPU 以及整體平台的介紹後,這篇就來看這次高通 Snapdragon X2 Elite/Extreme 處理器成長幅度也大的一塊:Hexagon NPU 的部分,其實負責 AI 運算的 NPU 設計在這幾年各家筆電處理器上都被視為相當重要的部分(畢竟微軟就是要推 Copilot+PC),但是各家所採取的策略又各有不同,像是 Intel 的 PantherLake 透過更大的矩陣配置提供更多算力, AMD 的 AI Max 則是在年初就推出了具備 50 TOPS 的 XDNA 架構 NPU 2 晶片,並且可使用系統主記憶體來增加記憶體配置。至於在高通這次的 Hexagon NPU 部分,更是一口氣將 AI 算力推升到 80 TOPS 的水準,可說是目前市場上筆電處理器中最高算力的 NPU 配置。
更多高通 Snapdragon X2 Elite 系列處理器介紹文章請見:
高通 Snapdragon X2 Elite 處理器深度剖析 Part 1 平台架構篇:效能/續航力/AI 功能我全都要!
高通 Snapdragon X2 Elite 處理器深度剖析 Part 2 Oryon CPU 篇:以更高時脈/更多核心數堆疊性能
高通 Snapdragon X2 Elite 處理器深度剖析 Part 3 Adreno X2 GPU 篇:顯示效能提升 2.3X 支援性更加完整

這部分的內容由高通的另一位副總 Lucian Codrescu 進行說明。

Lucian 一開始就點明了這次 Hexagon NPU 是目前市場上最快速的筆電 NPU 產品,最高能提供 80 TOPS 的 AI 算力,比起上一代要提升了 78% 的效能表現。

至於為何要一口氣拉到這麼高的設定?Lucian 表示主要是由於 AI 進化的速度真的太快了,基本上根本改變了使用者會在電腦的使用方式,包括工作型態、互動方式、甚至是作業系統運作等等,尤其是 AI 代理出現之後,更是加速了這樣的改變,每天都有不同的模型在筆記型電腦上運作,甚至是同時運作,所以高通認為需要為筆記型電腦帶來更強的 AI 加速性能,以滿足使用者未來的需求。

不過 Hexagon 處理器並非一開始就作為 NPU 進行發展,其實早在 2004 年,高通就為多媒體裝置的音訊處理開發了 Hexagon DSP 訊號處理器,這是一個可程式化的架構,使用了大量的乘法運算、重新解構數據並且在記憶體中重新配置以更有效地進行處理,並且還要針對電源效率進行最佳化。
接著來到 2014 年進入到智慧型手機世代,新增了很多圖像處理的需求,所以 Hexagon DSP 的工作也開始加入了圖像處理,除了加入影像濾波器的設計外,可以看到運算效能也比先前提高了 10 倍。而在 2019 年進入機器學習世代後,則是加入了矩陣運算以及 Tensor 加速器,並且把運算效能再提升 10 倍,不過仍然兼顧了電源效率表現。

而進入到 NPU 世代後,Hexagon NPU 仍然每年持續進行進化,Lucian 表示高通在這部分持續跟 Google 合作進行用於 NPU 機器學習神經網路,並且逐年進行迭代更新。而且這個架構不僅用於筆記型電腦上,也橫跨了手機/車載或是其他處理器,雖然功能略有不同,但是都是採用同樣的架構。
而從左側的架構圖中可以看出,相較於競爭對手的 NPU 強調增加 Matrix 矩陣的數量,甚至是將所有運算單元都改用矩陣設計,高通在 Hexagon NPU 仍然維持了 Scalar 純量、Vector 向量以及 Matrix 矩陣的平衡設計,以應對不同 AI 模型的需求,並且兼顧設計成本以及 NPU 的耗電量。從資料的處理程序可看出,所有的資料一開始都會利用純量單元進行處理,純量單元也會對接下來的向量以及矩陣單元進行工作的分配。而這些計算單元都與 L2 快取或是 Vettor TCM 單元緊密連結,透過 DMA 跟匯流排向 SOC 或主記憶體系統抓取資料進行處理。

Lucian 也展示了高通內部實際針對 300 款模型進行測試的結果,可以看到並不是所有 AI 模型都僅用到矩陣運算,還有相當多的部分使用向量甚至是純量運算,所以在這次高通的 Hexagon NPU 中仍然維持了平衡的系統設定,不僅在成本上可以獲得控制,在運算時也能獲得更好的功耗表現。
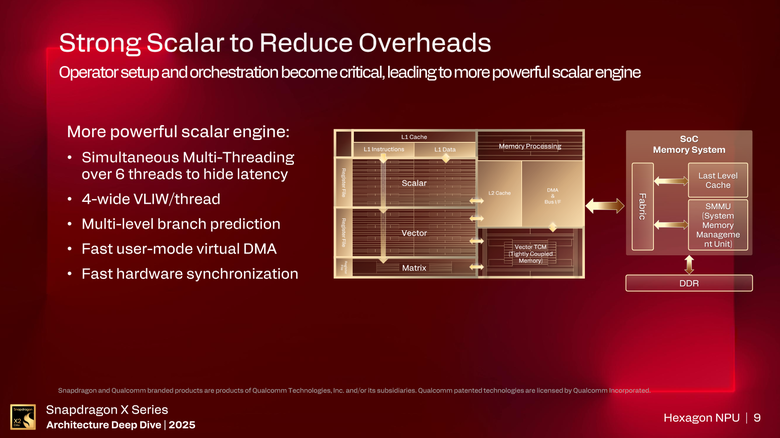
在純量單元部分,這次高通配置了 12 個執行緒,比起上一代多了一倍,並且導入了多層分支預測跟虛擬 DMA 的設計,來解決先前純量單元的同步延遲問題,增加執行緒間的互通性,以適應更大的 AI 模型需求,這也讓在前一代需要分割處理的運算,在這一代的 Hexagon NPU 中可以直接進行處理。

在這一代的 Hexagon NPU 純量處理部分提供了 12 執行緒的配置,另外也加大了記憶體頻寬以及 64 Bit DMA 定址能力。

這樣的配置讓這一代 Hexagon NPU 在純量的吞吐量上增加了 143%。

在匯流排頻寬上增加了 127%。

接著來看向量單元設計,這個部分 Hexagon NPU 提供了 8 組平行執行緒配置,並且具備 4 組 128B SIMD 指令,並且新增了 FP8 以及 BF16 資料格式的支援。

吞吐量部分則是比上一代提升了 143%。

至於在矩陣單元部分,除了支援 2 bit 權重外,也針對激勵函式以及深度捲積加入了硬體的支援,另外也透過獨立的電源軌以及權重/激勵快取設計,來減少矩陣元件的功耗,在不必要使用矩陣運算的時候,單獨降低元件的電壓。

不過雖然看起來在矩陣單元部分,高通主要著重在功耗的控制上,但是跟上一代相比,這次 Hexagon NPU 在矩陣部分仍有 78% 的吞吐量提升。

而在實際上的 AI 模型運作效能表現上,高通以 EDSR(Enhanced Deep Residual Networks for Single Image Super-Resolution)提升影像解析度的 AI 模型為例,這一代的 Snapdragon X2 Elite Extreme 處理器比起上一代的 Snapdragon X Elite 處理器,在同樣的 5W 功耗設定下,效能提升到 1.6 倍。

另外也透過更多資料格式的支援,在同樣的功耗下提供更高的算力表現。

(點擊可看大圖)所以以帳面算力來看,目前高通 Snapdragon X2 Elite 系列處理器的 80 TOPS 算力是目前市售筆記型電腦中最高的。

(點擊可看大圖)不過高通也知道 TOPS 基本上就是個各說各話的東西,所以也實際搬出了在測試軟體中的成績表現。在常見的 UL Procyon AI Computer Vision 分數中,高通 Snapdragon X2 Elite Extreme 處理器獲得 4151 分的成績,也比競爭對手要高出許多。

(點擊可看大圖)在另一款 GeekBench AI 1.5 版的測試部分,則是獲得了 88615 分的成績,同樣有相當大的領先成績。

(點擊可看大圖)另外在每單位功耗的效能表現部分,高通 Snapdragon X2 Elite Extreme 處理器也比競爭對手有最高 3.8X 的成績。

(點擊可看大圖)最後來看一下這次 高通 Snapdragon X2 Elite Extreme 處理器 Hexagon NPU 的特色總覽,包括比起上一代有 78% 的效能提升,80 TOPS 的算力、64 bit 定址支援、12 執行緒、8 組平行向量引擎等配置,並且兼顧效能以及功耗設計。
 感謝分享&介紹,Snapdragon X2 Elite ai功能不可少
感謝分享&介紹,Snapdragon X2 Elite ai功能不可少 































































































