U大中文版
雖然 Intel 是超級電腦排名常勝軍,
不過這次由穩定運行一年,
採用EPYC處理器的 Frontier 奪榜,
使用Intel處理器的 Aurora 排名第二,
不知道是不是當初 Intel 給DOE畫大餅畫太大...
畫到2 Exaflops

雖然營運多年,中途也不斷投增機組,
但至今組建規模能未達標...
當然,Intel Aurora 目前並非完全體,
未來組建完成運算力仍可能擠下Frontier。
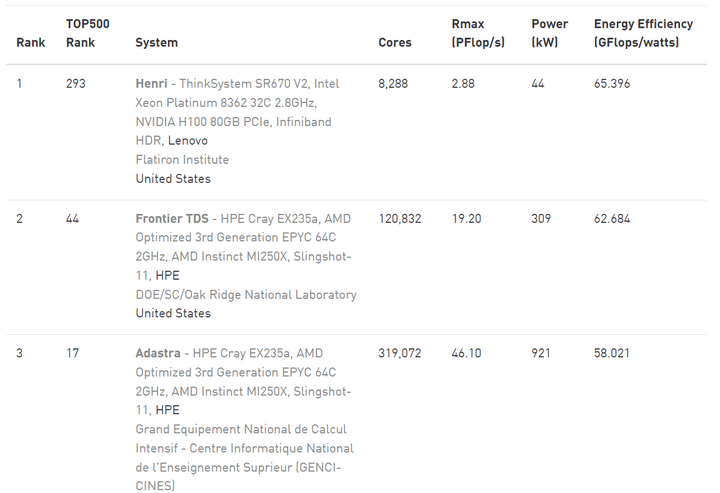
AMD Frontier 除了算力頂級之外,
也以超強的能源效率輾壓對手。