

路邊工程師又來更新近況啦。
當初購入 S5507QA 的時候心裡就一直有個疑問,到底那個 NPU 可以拿來做什麼,雖然我不是為了這個才買的。
某天跑客戶端除錯,習慣性的看完 log 打算餵狗,但是沒網路而且好死不死那邊是收訊死角,雖然最後是靠通靈跟經驗扛過去了,不過都 2025 了應該有更好的方法吧?
這時候就想到前陣子紅起來的 DeepSeek R1 ,一堆人在意他的潛在資安問題,畢竟是西台灣做的。
仔細想想,對耶,我可以跑本地端模型阿,於是有了這個測試。
一開始也沒多想,直接衝向之前有聽過的 ollama。
安裝不難,小黑窗對寫 code 的人來說也沒啥好怕,但就好像跟我想的不太一樣,Loading 幾乎都還是在 CPU 上阿,NPU 直接躺平。
接著換了套 LM Studio,這款原生支援 ARM 之外,有 GUI 還是比較親民。
安裝的時候直接提到 DeepSeek R1,既然你都問了,那恭敬不如從命。
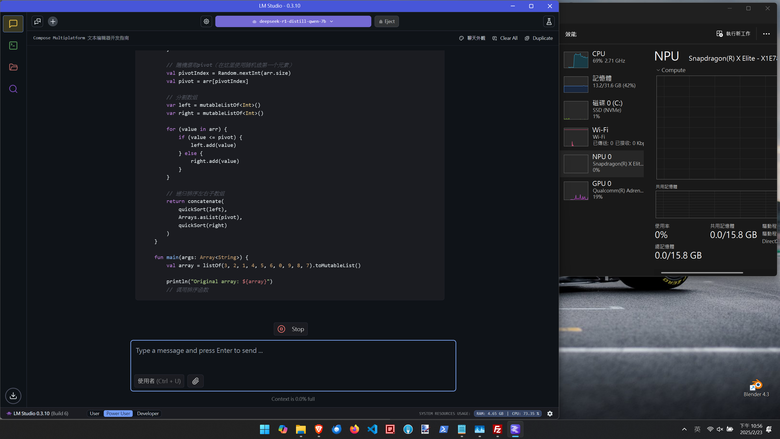
裝完之後試了一下,很顯然的他沒有用到 X Elite 的 NPU,負載全在 CPU 上,研究了一下好像沒看到 NPU。
『下面一位!』
後來翻翻找找看到另外一款,Anything LLM,同樣軟體部分也原生支援 ARM。
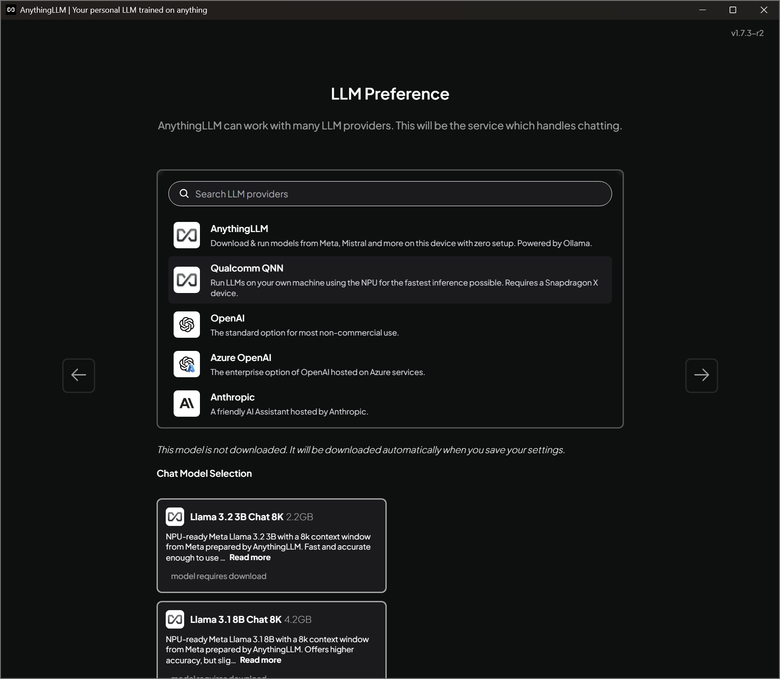
安裝時的時候會要你選模型,這邊要切到高通的 QNN,會有基於 Llama 3.x 的模型可以選。
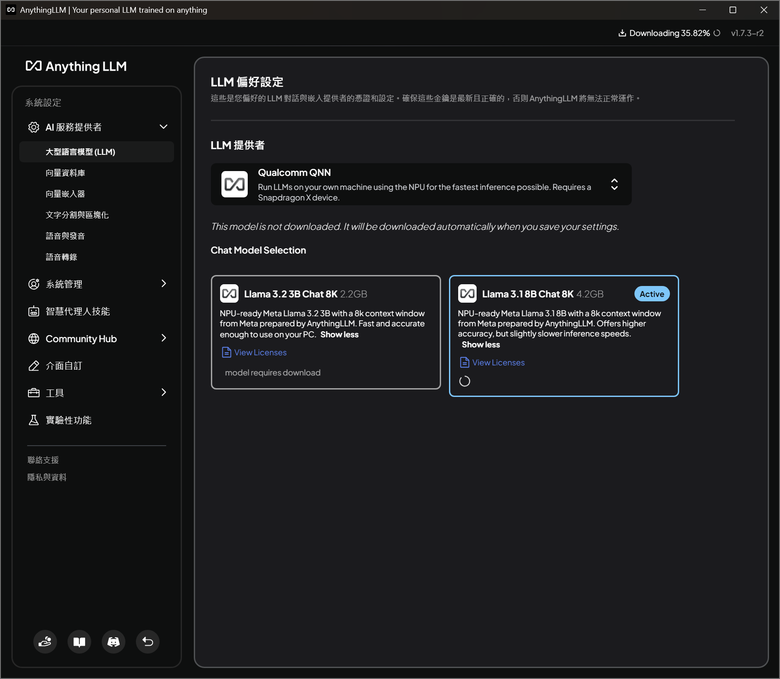
一開始沒選對的話也可以到設定裡面改。
對話的時候就會看到 NPU 跑滿有在做事了,感動。
另一個優點大概就是這是跑在本地端,所以沒有網路的話也可以用,也不用擔心資料外流 (?),我個人是覺得蠻好的,微軟的 Copilot 目前好像還是得連線才能用,至少我把網路關掉打開來看是一片空白。
AnythingLLM 也是可以用其他模型,包含前面測試的 DeepSeek R1,不過不意外的是用 CPU 在跑,過段時間應該就會有人 Porting 更多支援的模型了吧。

一樣都是在圓桌上用,一樣都喝咖啡,為什麼別人看起來好像都比較爽 (x

最後講講實際用起來的感覺吧。
先講缺點,比起雲上的服務,在筆電上跑,模型規模跟算力有差距是一定的,可以感覺內容回覆的慢一些,另外就是支援高通 NPU 可用的模型比較少,看起來應該是要先透過 QNN SDK 處理,不過我覺得這方面大概就跟相容性一樣,之後有更多機種加入之後應該可以玩的內容也會更多。好險我選的是 32G 的頂配版本,用 CPU 硬跑也還算可以,對我自己來說這算是不錯的附加價值,畢竟常常會在只有內網的情況下使用,快速翻查一些指令或是 snippet 還是很實用的,以上簡單分享給有興趣的人。
































































































